找到
97
篇与
寒烟似雪
相关的结果
-
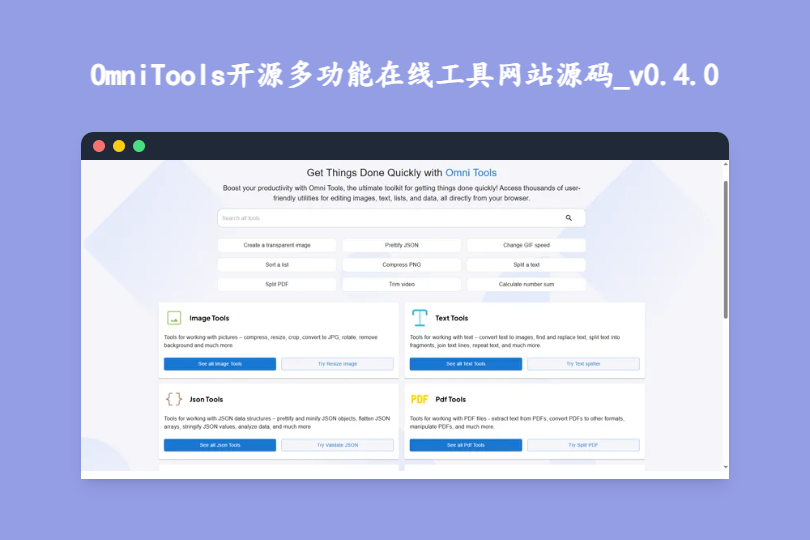
 OmniTools开源多功能在线工具网站源码_v0.4.0 OmniTools开源多功能在线工具网站源码_v0.4.0 一款专为简化日常各类技术与非技术任务打造的自托管Web应用,一站式覆盖编码辅助、图像/视频处理、PDF操作、数据分析等多领域需求,无需切换多个零散工具平台即可高效完成工作。 mm7ppdgr.png图片 项目定位与发布 该项目以开源形式发布于GitHub,面向所有有工具需求的用户,无论是开发者、设计师还是普通办公/学习人群,都能找到适配的功能。 部署方式 支持通过Docker命令一键快速部署到个人或团队的自有服务器中,部署命令如下: docker run -d --name omni-tools --restart unless-stopped -p 8080:80 iib0011/omni-tools:latest核心安全保障 所有文件处理、数据计算均在用户本地浏览器客户端完成,不会上传任何文件或数据到服务器,从根源上保障了用户的隐私安全与数据安全。 功能模块 1. 多媒体处理 图像工具 图像缩放 图像格式转换 视频工具 视频剪辑 视频倒放 2. 文本与数据处理 文本工具 大小写转换 列表随机化 文本格式化 日期与时间工具 日期计算器 时区转换器 数学工具 生成质数 生成完全数 3. 数据格式工具 JSON工具 PDF工具 CSV工具 源码特色 1. 自托管 用户可将项目完全部署在自有服务器上,拥有对工具站的完全控制权,同时结合客户端处理特性,进一步强化隐私保护。 下载 下载地址:https://pan.quark.cn/s/fb86894545d4 提取码: 2. 轻量级 Docker镜像大小仅为28MB,部署过程极其迅速简便,同时大幅降低了服务器的资源消耗。 3. 易扩展性 项目基于React和TypeScript构建,使用Material UI作为设计框架,同时采用Iconify的图标库,技术栈清晰规范。开发者可通过脚本轻松创建新的工具,命令如下: npm run script:create:tool my-tool-name folder1/folder2对于位于多层嵌套目录下的工具,也可通过类似命令快速创建。 项目总结 OmniTools是一个强大而灵活的开源工具集合,适用于需要频繁处理各种类型文件和技术任务的个人和团队。它的自托管特性、轻量化设计以及对隐私的高度重视,使其成为替代零散在线工具的理想解决方案。
OmniTools开源多功能在线工具网站源码_v0.4.0 OmniTools开源多功能在线工具网站源码_v0.4.0 一款专为简化日常各类技术与非技术任务打造的自托管Web应用,一站式覆盖编码辅助、图像/视频处理、PDF操作、数据分析等多领域需求,无需切换多个零散工具平台即可高效完成工作。 mm7ppdgr.png图片 项目定位与发布 该项目以开源形式发布于GitHub,面向所有有工具需求的用户,无论是开发者、设计师还是普通办公/学习人群,都能找到适配的功能。 部署方式 支持通过Docker命令一键快速部署到个人或团队的自有服务器中,部署命令如下: docker run -d --name omni-tools --restart unless-stopped -p 8080:80 iib0011/omni-tools:latest核心安全保障 所有文件处理、数据计算均在用户本地浏览器客户端完成,不会上传任何文件或数据到服务器,从根源上保障了用户的隐私安全与数据安全。 功能模块 1. 多媒体处理 图像工具 图像缩放 图像格式转换 视频工具 视频剪辑 视频倒放 2. 文本与数据处理 文本工具 大小写转换 列表随机化 文本格式化 日期与时间工具 日期计算器 时区转换器 数学工具 生成质数 生成完全数 3. 数据格式工具 JSON工具 PDF工具 CSV工具 源码特色 1. 自托管 用户可将项目完全部署在自有服务器上,拥有对工具站的完全控制权,同时结合客户端处理特性,进一步强化隐私保护。 下载 下载地址:https://pan.quark.cn/s/fb86894545d4 提取码: 2. 轻量级 Docker镜像大小仅为28MB,部署过程极其迅速简便,同时大幅降低了服务器的资源消耗。 3. 易扩展性 项目基于React和TypeScript构建,使用Material UI作为设计框架,同时采用Iconify的图标库,技术栈清晰规范。开发者可通过脚本轻松创建新的工具,命令如下: npm run script:create:tool my-tool-name folder1/folder2对于位于多层嵌套目录下的工具,也可通过类似命令快速创建。 项目总结 OmniTools是一个强大而灵活的开源工具集合,适用于需要频繁处理各种类型文件和技术任务的个人和团队。它的自托管特性、轻量化设计以及对隐私的高度重视,使其成为替代零散在线工具的理想解决方案。
-
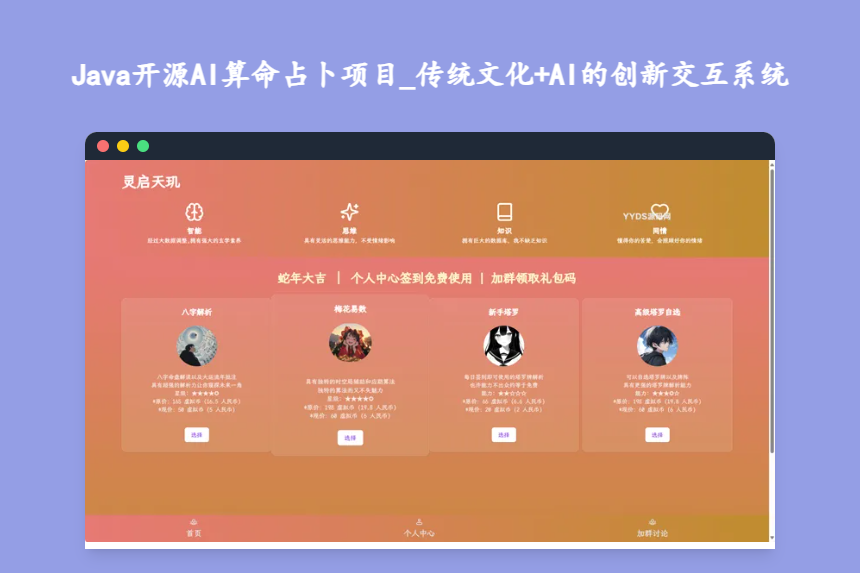
Java开源AI算命占卜项目_传统文化+AI的创新交互系统 Java开源AI算命占卜项目:传统文化+现代AI的创新交互系统 一款融合前沿AI算法与传统玄学文化的开源AI算命占卜系统,采用前后端分离架构,功能覆盖解卦、塔罗占卜、八字命理等核心场景,同时支持用户管理、历史记录、多语言框架、模型集成、支付功能等扩展能力,源码结构清晰、模块化设计,文档配置齐全,非常适合开发者学习研究或二次开发商用。 mm5mj4nd.png图片 一、核心技术架构 后端技术栈 编程语言:Java 21 核心框架:Spring Boot,保障系统高性能与可扩展性 数据存储:MySQL 8,用于持久化用户数据、占卜记录、支付配置等核心信息 性能优化:Redis缓存,提升高频访问数据的读取速度,满足高并发场景需求 前端技术栈 构建环境:NodeJS 20+ 核心框架:React,打造界面美观、交互流畅的用户端体验 交互方式:通过API调用后端服务完成所有核心业务逻辑 二、核心功能模块 1. 解卦功能 根据用户输入的生辰八字等关键信息,自动生成对应的卦象,并结合AI算法与传统解卦逻辑,生成兼具科学性与趣味性的个性化解析内容。 2. 塔罗占卜功能 支持多种塔罗牌抽牌模式,用户可根据自身需求选择不同的牌阵,系统结合AI算法对抽取的牌面进行深度解读,提供专属的运势建议。 3. 八字命理功能 分析用户的完整八字信息,从命局层次、性格特征、事业财运、感情婚姻、健康状况等多个维度进行预测,为用户提供全面的运势参考。 4. 支付功能 支持付费解锁高级功能,例如更详细的占卜解读、个性化定制服务、专属时空局辅助解析等,满足不同用户的需求层次。 三、扩展功能模块 1. 用户管理 包含完整的用户注册、登录、个人资料维护、密码找回等功能,保障用户账户安全与使用便捷性。 2. 历史记录 自动保存用户的所有占卜记录,用户可随时在个人中心查看历史解析内容,方便对比不同时间的运势变化。 3. 多语言框架 虽然目前系统仅支持中文,但整体框架设计允许开发者轻松添加其他语言,满足国际化运营需求。 4. 模型集成 支持接入不同的AI大模型或专业预测模型,开发者可根据自身需求替换或升级模型,以实现更精准、更个性化的预测效果。 5. 支付平台接口更换 系统默认提供易支付接口配置,但同时支持开发者更换为其他主流支付平台接口,适应不同的业务场景与运营需求。 四、源码核心特色 1. 技术栈先进 采用当前主流的前后端分离技术架构,后端Spring Boot、前端React、MySQL+Redis数据存储,技术成熟稳定,社区资源丰富,便于开发者学习与维护。 2. 开放性强 提供详细的开发文档与配置说明,开发者可快速上手部署与二次开发; 源码结构清晰,采用模块化设计,各功能模块相互独立,便于维护与扩展; 支持更换AI模型、支付平台接口等核心组件,灵活性极高。 3. 文化融合 将传统算命文化(解卦、八字命理、塔罗占卜等)与现代AI技术完美结合,既保留了传统文化的精髓,又通过AI算法提升了解析的个性化与趣味性,为用户提供了一种全新的算命占卜体验。 五、部署指南 前端部署 环境准备 安装NodeJS 20+版本; 确保后端服务(AI-Diviner-Server)已正常运行。 配置步骤 修改src/lib/untils.ts文件中的API_URL,设置为后端服务的完整地址(注意不要带最后的斜杠/); 依次运行以下命令完成项目依赖安装与打包: npm install npm run build 后端部署 环境准备 安装Java 21、MySQL 8以及Redis; 准备好自己的AI模型密钥和支付平台账户。 配置步骤 修改src/main/resources/application.yml文件,更新数据库和Redis的连接配置; 修改src/main/java/fun/diviner/ai/entity/Special.java文件中的authSecret字段,设置为自己的密钥; 在src/main/java/fun/diviner/ai/diviner/ai/AIModel.java中填入自己的AI模型密钥; 将项目根目录下的data.sql文件导入到MySQL数据库中; 修改数据库中core表的相关支付配置字段: yiPayId:易支付ID; yiPayMerchantPrivateKey:易支付商户私钥; yiPayPlatformPublicKey:易支付平台公钥; yiPayNoticeUrlPrefix:易支付后端回调前缀(如https://api.ai.diviner.fun); yiPayReturnUrl:易支付前端回调地址(填写前端网址); 依次运行以下命令完成项目依赖安装与打包: mvn clean package 使用以下命令启动项目: java -jar target/ai-diviner-1.0.0.jar下载 下载地址:https://pan.quark.cn/s/f5c7cdadc5b2 提取码: 六、项目总结 这款Java开源AI算命占卜项目是一款极具创新性的开源项目,它将AI技术与传统文化完美结合,为用户提供了一种全新的、兼具科学性与趣味性的算命占卜体验。无论是对于想了解传统文化的普通用户,还是希望学习前后端分离架构、AI模型集成、支付系统开发等技术的开发者来说,这款项目都具有很高的学习价值与商用潜力。
-
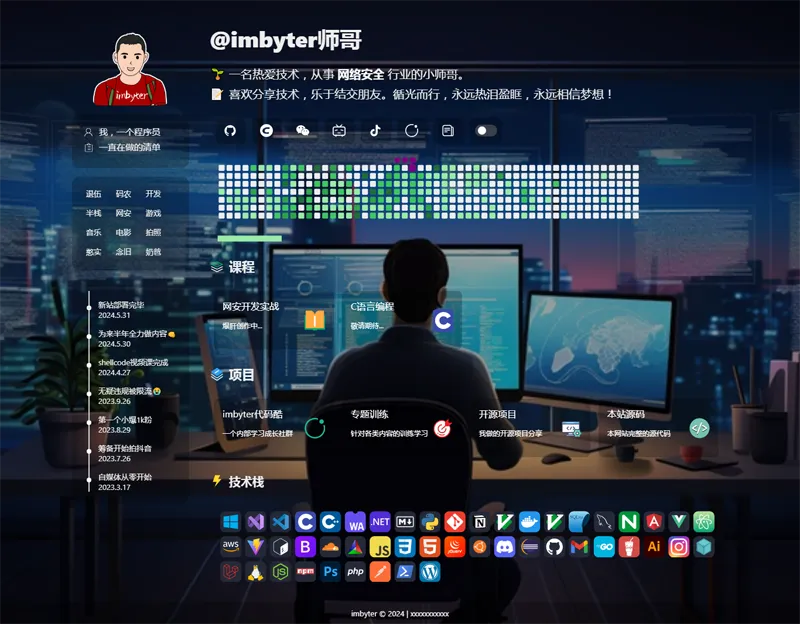
HTML 暗黑炫酷程序员个人主页源码 开源免费响应式可定制 HTML暗黑炫酷风程序员个人主页源码 开源免费可定制 这款专为程序员打造的暗黑风格个人主页源码,依托HTML、CSS与JavaScript三大核心技术栈开发,是适配程序员打造专属个人展示平台的优质模板。该源码以极具科技感的暗黑风格为核心设计基调,既贴合程序员的审美偏好,又配备了丰富的个性化定制选项,开发者可根据自身需求轻松修改,打造独属于自己的个人主页。无论是用来展示个人开发项目、分享技术博客内容,还是交流编程实战经验,这款源码都能全方位满足使用需求。 mld2tdvc.png图片 核心功能亮点 暗黑风格界面设计 采用当下热门的暗黑系界面设计,整体视觉效果炫酷且充满科技感,高度契合程序员的审美需求。同时,暗黑显示模式能有效减少屏幕光线对眼睛的刺激,缓解长时间浏览网页带来的眼部疲劳,更适合程序员日常的使用习惯。 全端响应式适配 源码支持完善的响应式设计,能够智能适配桌面电脑、平板电脑、智能手机等不同尺寸的终端设备,无需单独为不同设备做适配开发,无论访问者使用何种设备打开主页,都能获得流畅、舒适的浏览体验。 个人项目便捷展示 源码内置专门的项目展示模块,开发者可简单快捷地添加、编辑项目信息,包括项目名称、功能描述、项目截图以及项目地址等内容,能够直观、清晰地向访问者展示自身的技术实力与项目开发经验。 技术博客无缝集成 针对有技术博客的开发者,源码支持博客内容的集成展示,可将博客文章的链接或内容摘要添加至个人主页,让访问者能够直接在主页上浏览、跳转至博客内容,提升技术分享的便捷性。 社交媒体链接整合 源码设置了社交媒体链接专区,开发者可自由添加GitHub、LinkedIn、Twitter等主流技术社交平台的账号链接,方便行业伙伴、访问者进行关注与互动,搭建个人的技术社交桥梁。 源码专属特色 高度个性化可定制 提供多维度的自定义设置选项,覆盖页面颜色、字体样式、整体布局等多个方面,开发者可根据自身喜好打造专属视觉风格。同时源码的代码结构清晰明了,关键位置都配有详细注释,即便没有丰富前端开发经验的初学者,也能轻松上手修改。 丰富动画提升交互 为增强页面的交互体验,源码中融入了多种趣味动画效果,包含页面加载时的过渡动画、鼠标悬停元素时的动态效果等。这些动画让静态的网页变得生动有趣,还能有效引导访问者的注意力,提升页面的整体交互感。 优质代码保障性能 源码的编写严格遵循前端开发的最佳实践与行业编码规范,代码质量处于较高水平。不仅能为开发者提供优秀的代码风格参考,帮助其学习并提升前端开发能力,同时高质量的代码也从底层保障了个人主页运行的稳定性与流畅性。 开源免费零成本使用 该个人主页源码为开源免费的资源,开发者可自由下载、直接使用,也能根据实际需求进行二次开发与功能扩展。这一特性大幅降低了程序员打造个人主页的开发成本,让开发者无需投入额外成本就能拥有专属的展示平台。 总结 这款HTML暗黑炫酷风程序员个人主页源码,是一款兼顾实用性与美观性的优质模板,以暗黑风格为核心,搭配完善的功能模块与高度的可定制性,能充分满足程序员展示个人项目、分享技术内容的核心需求。同时其优质的代码编写、丰富的动画效果,以及开源免费的特性,让它成为程序员打造个人主页的优选模板。如果你正想搭建一个极具个性的程序员个人主页,这款功能齐全、上手简单的HTML源码绝对值得尝试。 下载 下载地址:https://pan.quark.cn/s/16e8d253a6d7 提取码:
-
华为花瓣测速 app 官方版_Android 专业网络测速工具下载 华为花瓣测速:专业手机网络测试工具,轻松掌握网络状态 在移动网络和WIFI网络高频使用的当下,一款精准的网络测速工具能帮我们快速掌握网络状况,华为花瓣测速便是这样一款专为Android用户打造的专业网络工具,其最新版为v4.8.0.303,软件大小39.31MB,于2023年11月23日完成更新,凭借全面的功能和便捷的操作,成为不少用户检测网络的首选。 mlchuz7p.png图片 华为花瓣测速是集成了移动网络与WIFI网络上传、下载测试,以及网络诊断功能的工具,适配运营商2G/3G/4G/5G全制式网络,同时也支持WIFI网络的各项测试,还能完成时延抖动测试与网络诊断,实时且准确地为用户反馈当前的网络状态,安装简单、操作便捷、结果精准是其核心特点,即使是网络操作新手,也能轻松上手使用。 这款软件的界面设计简洁友好,主打一键测速功能,点击后可快速出测试结果,无需复杂的操作步骤。测速结果的展示也十分全面,不仅能显示待测网络的运营商名称、测试的城市位置,还能清晰呈现Ping时延、上传速率、下载速率、网络抖动以及丢包率等关键网络指标,让用户对网络状况有全方位的了解。同时,软件还能帮助用户分析网络波动的原因,甚至支持对蹭网用户进行限速管理,助力用户打造更极速、稳定的网络环境。 在功能层面,华为花瓣测速做到了多维度覆盖,满足用户不同的网络检测需求。信号测试功能可专门检测Wifi信号,帮助用户寻找周边更强的Wifi信号源;网络诊断功能能精准检测当前网络的连接状况,快速定位网络问题的根源,让用户针对性解决网络故障;附近网速功能依托地图定位,直观展示周边其他用户的网速快慢,为用户选择网络提供参考;网速排名功能则会展示用户的网速在同类测试中的名次,让用户清晰知晓自己的网络速度水平。 下载 下载地址:https://pan.quark.cn/s/449bca259955 提取码: 除了基础的测速和诊断功能,华为花瓣测速还有不少实用的特色设计。软件可自动保存所有测试过的网速数据信息,方便用户后续查看和对比网络状态的变化;测速结果中会同步显示测试的服务器IP和用户的手机型号,让测试数据更具参考性;在测速过程中,会以实时图形的形式展示当前的下载或上传速度,让用户直观看到网速的实时变化;同时能全方位测试网络延迟、下载速度、上传速度等核心指标,让用户对网络的各项性能了如指掌。 无论是日常刷视频、玩游戏时想检测网络是否卡顿,还是办公时排查网络传输问题,亦或是发现网络变慢后寻找问题根源,华为花瓣测速都能凭借全面的功能和精准的测试结果,为用户提供有效的网络检测支持,是一款实用性极强的手机网络管理工具。
-
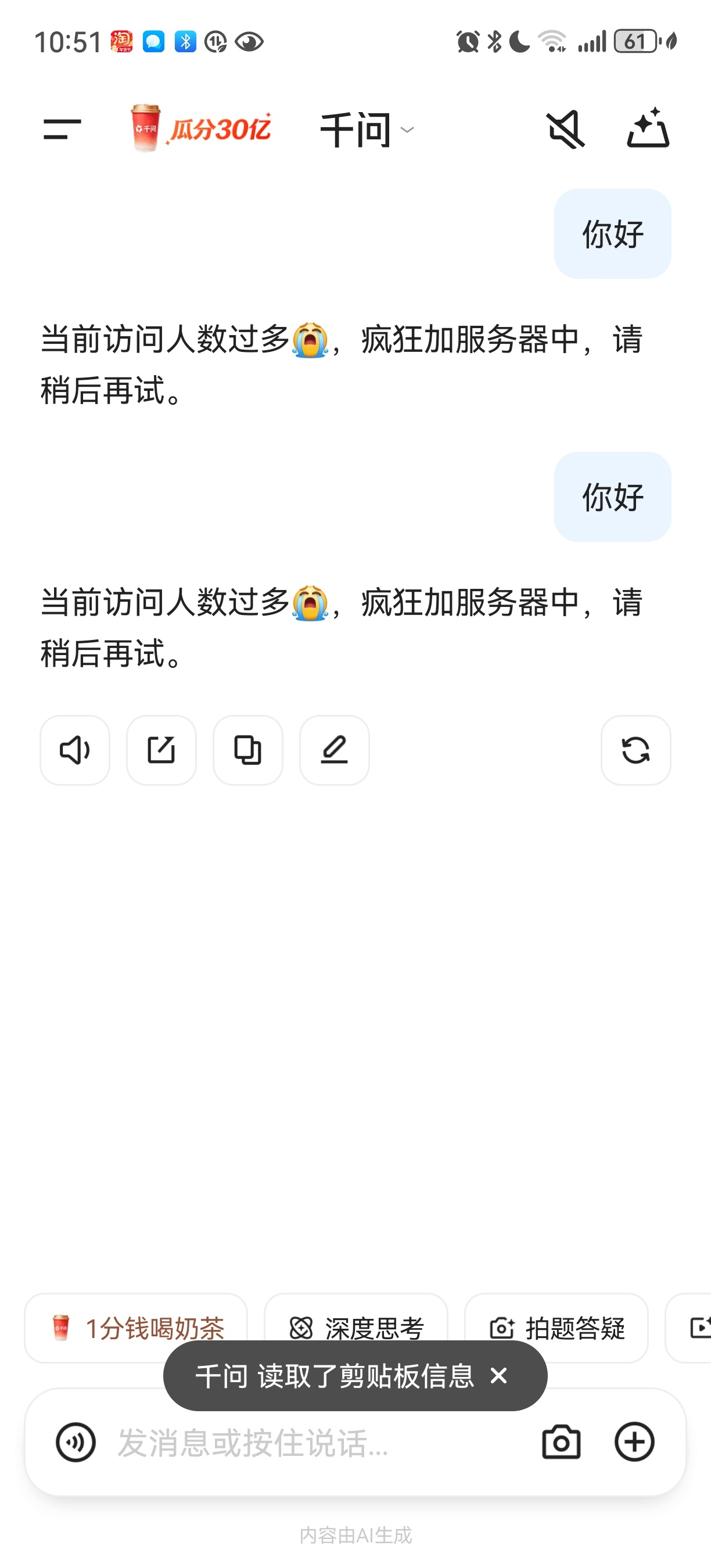
崩服预警!千问 30 亿免费奶茶硬刚元宝:登录领 25 元免单卡,无套路直喝 崩服预警!千问狂撒30亿请喝免费奶茶,硬刚元宝拉人头套路 “当前访问人数过多 😂,疯狂加服务器中,请稍后再试。” mlaamols.png图片 看着聊天框里重复弹出的过载提示,我才反应过来——不是我的网络出了问题,是千问的服务器,被全网想喝免费奶茶的网友们挤到“冒烟”了。这场号称“瓜分30亿”的福利活动,不仅是一次简单的用户回馈,更是千问针对腾讯元宝“拉人头红包”的一场正面反击战。 福利直给:1分钱喝奶茶,登录就领无套路 千问这次的宣传核心只有一个字:送。没有复杂的任务,没有烦人的社交裂变,主打一个“真诚换流量”。 ✅ 核心福利:登录千问即可领取25元无门槛免单卡,可直接兑换奶茶、咖啡、外卖等实物,相当于免费喝奶茶;另有10亿现金红包可抽,额外邀请好友还能解锁更多免单机会。 ✅ 参与入口:直接点击下方链接,跳过卡顿的聊天框,直达活动页面薅羊毛: 千问30亿免费奶茶活动入口 ✅ 活动亮点:哪怕不邀请任何好友,也能拿到基础免单卡,完美戳中用户对“拉人头套路”的反感点。 正面硬刚:千问VS元宝,AI红包大战的核心差异 正如你所洞察的,这场“免费奶茶”狂欢,本质是千问对腾讯元宝的精准反击。两大AI平台的红包活动,玩法差异堪称“套路与反套路”的对决: 对比维度千问(30亿福利)腾讯元宝(10亿现金)核心福利20亿免单卡(免费奶茶/外卖)+10亿现金纯现金红包参与门槛登录即领基础免单卡,无需拉人头必须分享链接邀请好友,才能获得抽奖次数活动逻辑降低门槛,用实物福利吸引泛用户绑定微信生态,靠社交裂变强制拉新用户体验无套路直给,好感度拉满分享压力大,易引发社交反感投入规模30亿总预算,元宝的3倍10亿现金,主打“现金诱惑”崩服的真相:用户用脚投票,反感“拉人头” 从“发送点奶茶指令无响应”到“统一弹出过载提示”,千问服务器的崩溃,恰恰印证了一个事实:用户早就受够了“拉人头”的套路。 腾讯元宝的现金红包虽然诱人,但“必须邀请好友”的规则,让很多人陷入“不分享就没福利”的尴尬;而千问的“免费奶茶”精准切中痛点——不需要麻烦亲友,不需要在朋友圈刷屏,点进链接就能领福利。这种“反套路”的玩法,直接引爆了用户热情,短时间内的流量洪峰,连大厂的服务器都没能扛住。 薅羊毛小贴士(避坑版) 目前千问已在紧急扩容,想要领到免费奶茶的网友,可以参考以下步骤: 切换网络 若页面显示“人数过多”,可错峰参与(避开10:00-12:00高峰时段); 领取免单卡后,尽快在活动页兑换奶茶,避免卡券过期; 邀请好友可额外领卡,但非强制,按需选择即可。 这场AI红包大战,千问用“免费奶茶”和“无套路”,在用户心智中狠狠刷了一波好感。虽然服务器崩了,但赢了人心——毕竟,谁能拒绝一杯不需要“拉人头”的免费奶茶呢?
-
YOLOv8自定义数据集制作与训练教程|训练专属检测模型 YOLOv8实战:从零制作自定义数据集,训练专属检测模型 前两章我们搞定了环境搭建和基础推理,能处理图片、视频,但用的都是官方预训练模型,只能检测80类通用目标(比如人、车、猫)。实际做项目时,肯定要检测自己的专属目标——比如检测工厂的零件缺陷、自家宠物、特定商品,这就需要做自定义数据集,训练专属模型。这一章全程手把手带做,从标注工具安装到训练出第一个自己的模型,所有步骤都拆到新手能看懂,代码直接复用。 ml7hddwt.png图片 一、前期准备:明确目标+选对工具 1. 先定检测目标(新手别贪多) 新手第一次做,别选太复杂的目标(比如检测细小的电子元件),选2-3类简单目标即可,比如: 日常物品:水杯(cup)、键盘(keyboard)、鼠标(mouse) 宠物类:自家的猫(cat)、狗(dog) 场景类:椅子(chair)、桌子(table) 我以“检测水杯、键盘、鼠标”为例,全程演示,你可以替换成自己要检测的目标。 2. 标注工具选LabelImg(新手首选) YOLOv8需要YOLO格式的标注文件,LabelImg是最经典、最容易上手的标注工具,支持一键导出YOLO格式,不用手动改格式,完美适配新手。 二、LabelImg安装(Windows/Mac通用) 1. 安装前置依赖 LabelImg基于Python和PyQt5,先装PyQt5: # Windows pip install pyqt5 lxml # Mac/Linux pip3 install pyqt5 lxml2. 安装LabelImg 两种方式,选一种就行: 方式1:pip直接安装(推荐) # Windows pip install labelimg # Mac/Linux pip3 install labelimg方式2:GitHub克隆安装(备用,解决pip安装失败) # 克隆仓库(需要装git,没装的话先装git) git clone https://github.com/HumanSignal/labelImg.git cd labelImg # 安装并运行 python setup.py install3. 验证安装(启动LabelImg) 打开终端,输入: # Windows/Mac通用 labelImg回车后会弹出LabelImg的可视化窗口,说明安装成功;如果报错“找不到命令”,重启终端或检查Python环境变量(上一章提过的PATH问题)。 三、制作YOLO格式自定义数据集(核心步骤) 1. 先建标准文件夹结构 YOLOv8对数据集路径、文件夹命名有严格要求,先按下面的结构建好文件夹(纯英文命名,别用中文/空格): my_custom_dataset/ # 总文件夹 ├── images/ # 图片文件夹 │ ├── train/ # 训练集图片(80%) │ └── val/ # 验证集图片(20%) └── labels/ # 标注文件文件夹 ├── train/ # 训练集标注文件(和train图片一一对应) └── val/ # 验证集标注文件(和val图片一一对应)操作步骤: 新建总文件夹my_custom_dataset,放在桌面(方便查找); 里面建images和labels两个子文件夹; images里再建train和val,labels同理。 2. 准备图片并划分训练/验证集 找20-50张包含“水杯、键盘、鼠标”的图片(数量不用多,新手先跑通流程); 选16-40张放入images/train(训练集,占80%),剩下的4-10张放入images/val(验证集,占20%); 所有图片重命名为纯英文+数字,比如img_001.jpg、img_002.jpg(避免中文/特殊字符报错)。 3. 用LabelImg标注图片(逐步教) 标注的核心是“给每张图片里的目标画框,指定类别,导出YOLO格式标注文件”,步骤如下: 步骤1:设置标注环境 打开LabelImg,点击左上角File → Change Save Dir,选择labels/train(先标注训练集); 点击左上角View,勾选Auto Save Mode(自动保存,不用手动点保存); 点击左侧YOLO(切换到YOLO标注格式,关键!默认是PascalVOC,要切换)。 步骤2:加载图片并标注 点击左上角Open Dir,选择images/train,加载训练集图片; 按快捷键W,调出标注框工具,用鼠标框选图片里的“水杯”; 弹出“Enter label”对话框,输入类别名(比如cup,小写!),点击OK; 继续框选同一张图里的“键盘”(输入keyboard)、“鼠标”(输入mouse); 按快捷键D,切换到下一张图片,重复标注; 标注完所有训练集图片后,同理切换Save Dir到labels/val,标注验证集图片。 步骤3:检查标注文件 标注完成后,labels/train和labels/val里会出现和图片同名的.txt文件(比如img_001.txt),这就是YOLO格式标注文件,打开一个看看,格式如下(每行代表一个目标): 0 0.45 0.52 0.30 0.40 # 类别编号 中心点x 中心点y 框宽 框高(都是归一化值,不用改) 1 0.78 0.65 0.25 0.354. 新建类别映射文件(classes.txt) 在my_custom_dataset根目录下,新建classes.txt文件,按顺序写入所有类别名(每行一个),比如: cup keyboard mouse这个文件用来关联“类别编号”和“类别名”,比如编号0对应cup,1对应keyboard,必须和标注时输入的名称一致! 四、编写数据集配置文件(yaml文件) YOLOv8训练需要一个yaml文件,告诉模型“数据集在哪、有多少类、类别名是什么”,这是新手最容易出错的环节,我直接给模板,你改路径和类别即可。 在my_custom_dataset根目录下,新建custom_dataset.yaml文件,内容如下(重点改path!): # 数据集根路径(绝对路径!新手别用相对路径,避免找不到) # Windows示例:path: C:/Users/你的用户名/Desktop/my_custom_dataset # Mac示例:path: /Users/你的用户名/Desktop/my_custom_dataset path: C:/Users/xxx/Desktop/my_custom_dataset # 训练集/验证集图片路径(基于上面的path,不用改) train: images/train val: images/val # 类别数(我这里是3类:cup、keyboard、mouse,按自己的改) nc: 3 # 类别名(和classes.txt一致,顺序也必须一致!) names: ['cup', 'keyboard', 'mouse'] ⚠️ 关键坑:path必须写绝对路径!比如Windows路径是C:/Users/张三/Desktop/my_custom_dataset(别用反斜杠\,用/),Mac路径是/Users/张三/Desktop/my_custom_dataset,写错路径训练时会提示“找不到数据集”。 五、训练自定义YOLOv8模型(核心代码) 所有准备工作完成后,训练代码非常简洁,基于ultralytics库一键训练,新手不用改复杂参数,先跑通再说。 完整训练代码 from ultralytics import YOLO # 1. 加载预训练模型(用yolov8s,轻量均衡,新手首选) model = YOLO('yolov8s.pt') # 2. 开始训练(核心参数只改data路径) results = model.train( data='C:/Users/xxx/Desktop/my_custom_dataset/custom_dataset.yaml', # 你的yaml文件绝对路径 epochs=50, # 训练轮数:新手50-100足够,数据少就少点(比如30) batch=8, # 批次大小:CPU/低配GPU设4-8,高配GPU设16-32 imgsz=640, # 输入图片尺寸:默认640,不用改 device=0, # 设备:0=GPU(有N卡就用),-1=CPU(无GPU) patience=10, # 早停:10轮没提升就停止,避免过拟合 save=True, # 自动保存最佳模型 project='runs/train',# 训练结果保存目录 name='custom_model' # 本次训练名称,方便区分 ) # 训练完成后,最佳模型会保存在 runs/train/custom_model/weights/best.pt print("训练完成!最佳模型路径:", results.save_dir + "/weights/best.pt")训练过程监控 运行代码后,终端会打印训练日志,重点看两个指标: mAP50:平均精度,数值越高(0-1),模型效果越好; loss:损失值,随着训练轮数增加,应该逐渐降低并趋于稳定。 训练过程中,还会自动生成runs/train/custom_model文件夹,里面有训练曲线图、验证集检测示例、模型权重文件,不用手动管。 六、用自定义模型推理(验证效果) 训练完成后,用自己训的best.pt模型检测图片,验证是否能识别自定义目标: from ultralytics import YOLO # 加载自己训练的最佳模型 model = YOLO('runs/train/custom_model/weights/best.pt') # 检测一张包含水杯/键盘/鼠标的图片 results = model( source='test_custom.jpg', # 自己的测试图片 conf=0.5, # 置信度调高,避免误检 save=True ) # 打印检测结果 print("自定义模型检测结果:") for box in results[0].boxes: class_name = results[0].names[int(box.cls)] confidence = round(float(box.conf), 2) print(f"目标:{class_name},置信度:{confidence}")运行后,会生成带标注框的结果图,能清晰看到自己标注的“cup/keyboard/mouse”被识别出来,就算训练成功了! 七、本章常见问题与解决方法 训练报错“Dataset not found” 原因:yaml文件里的path路径错误、数据集文件夹结构不对、图片/标注文件缺失 解决:核对绝对路径是否正确,确保images/train和labels/train里的文件一一对应(图片和txt文件名完全一致)。 训练时显存不足(CUDA out of memory) 原因:batch批次太大、模型版本太高(比如用yolov8l/x) 解决:把batch降到4甚至2,换回yolov8n/s模型,或用CPU训练(device=-1)。 标注文件报错“IndexError: list index out of range” 原因:类别编号超出范围(比如标注了4类,但yaml里nc=3)、classes.txt和标注类别名不一致 解决:核对nc数值和实际类别数一致,类别名大小写/拼写完全匹配。 训练完成后检测不到自定义目标 原因:标注图片数量太少、标注框不准确、训练轮数不够 解决:增加标注图片数量(至少20张),重新标注确保框准确,把epochs调到80-100。 八、本章小结 这一章我们完成了“自定义数据集制作→配置文件编写→模型训练→推理验证”的全流程,核心是“先搭对文件夹结构、选对标注格式、写对yaml路径”,这三个环节不出错,训练基本就能跑通。 新手第一次训练效果可能不完美(比如漏检、误检),不用急,后续可以通过增加标注数据、调整训练参数(比如batch、epochs)、优化标注质量来提升。下一章我们会专门讲“YOLOv8训练调参技巧”,教你怎么用最少的改动,让模型效果翻倍。
-
YOLOv8实战进阶|单图、视频、批量推理与基础参数调优教程 YOLOv8实战进阶:单图、视频、批量推理与基础参数调优 上一章我们完成了YOLOv8最基础的环境搭建和单张图片检测,成功跑出了第一个带标注框的结果。但在实际使用里,只处理单张静态图片远远不够,视频检测、批量图片处理、调整检测精度和速度,才是日常高频用到的功能。这一章就顺着上一章的代码,在不改动核心逻辑的前提下,扩展常用推理场景,同时讲清楚新手最先用到的几个参数,所有代码都可以直接复制运行,配合上一章的环境直接使用。 ml2hyuoz.png图片 一、模型规格切换与选用建议 YOLOv8官方提供了多种不同大小的预训练模型,分别是yolov8n、yolov8s、yolov8m、yolov8l、yolov8x,后缀字母对应模型参数量和计算量,直接影响检测速度和精度,新手可以根据硬件直接选择。 yolov8n:nano,最小最快,精度一般,适合CPU、低配设备、嵌入式端 yolov8s:small,轻量均衡,CPU运行流畅,精度比n版提升明显,日常测试首选 yolov8m:medium,中等规模,精度较好,建议有独立显卡使用 yolov8l:large,大模型,高精度,需要中端以上NVIDIA显卡 yolov8x:xlarge,最大模型,精度最高,对显卡显存要求高 模型切换不需要修改代码逻辑,只需要更换加载的模型文件名即可。上一章我们用的是yolov8n.pt,想要换成s版,只需要修改一行代码: from ultralytics import YOLO # 替换为yolov8s.pt,首次运行会自动下载模型文件 model = YOLO('yolov8s.pt')硬件配置普通、仅做学习测试,优先保留n版或s版;有GPU且追求检测效果,再逐步升级到m、l、x版,不建议新手一上来用大模型,容易出现加载慢、显存不足的问题。 二、单张图片推理进阶用法 基础单图检测只能实现默认检测和保存,实际使用中我们经常需要指定保存目录、关闭冗余输出、只提取检测结果数据,这里整理可直接使用的进阶代码。 from ultralytics import YOLO # 加载s版均衡模型 model = YOLO('yolov8s.pt') # 单图推理,增加常用参数 # source:图片路径 # conf:置信度阈值,低于该值的目标不显示 # save:是否保存结果图片 # project:保存结果的根文件夹 # name:本次推理的结果子文件夹 # verbose:关闭终端冗余日志输出 results = model( source='test.jpg', conf=0.3, save=True, project='runs/detect', name='my_single_result', verbose=False ) # 解析并结构化打印结果 print("=== 单图检测详细结果 ===") for idx, box in enumerate(results[0].boxes): cls_id = int(box.cls) class_name = results[0].names[cls_id] conf = round(float(box.conf), 2) # 检测框坐标信息 (x1, y1, x2, y2) xyxy = box.xyxy.cpu().numpy().tolist()[0] print(f"目标{idx+1} | 类别:{class_name} | 置信度:{conf} | 坐标:{xyxy}")运行后,结果会统一保存在runs/detect/my_single_result目录下,方便多次测试区分不同版本的输出,同时终端只打印结构化的关键信息,不会被大量日志干扰。 三、视频文件目标检测 图片检测是基础,视频检测是YOLOv8的高频实用场景,代码逻辑和单图完全一致,只需要将source参数替换为视频文件路径,模型会自动逐帧处理并输出带检测框的视频。 操作准备 准备一段常见格式的视频,如mp4、avi、mov,文件名改为英文,如test_video.mp4 将视频和代码文件放在同一目录 完整视频检测代码 from ultralytics import YOLO model = YOLO('yolov8s.pt') # 视频推理,新增帧率相关与保存参数 results = model( source='test_video.mp4', conf=0.3, save=True, project='runs/detect', name='my_video_result', verbose=False, # 保留视频音频,可选 save_audio=True ) print("视频检测完成,结果保存在runs/detect/my_video_result目录")硬件说明: CPU环境:可以处理短时长、低分辨率视频,处理速度慢于原视频帧率,属于正常现象 GPU环境:可以流畅处理1080P及以下视频,处理速度接近实时 输出的视频文件会自动存放在指定目录,文件名包含处理标识,可直接用播放器打开查看逐帧检测效果。 四、批量图片批量推理 日常工作中经常需要一次性处理一整个文件夹的图片,逐张手动运行效率太低,YOLOv8支持直接传入文件夹路径,自动批量处理所有图片,无需编写循环代码。 操作准备 新建一个文件夹,命名为batch_images 将所有需要检测的图片放入该文件夹,全部使用英文文件名 保证batch_images和代码文件在同一级目录 批量检测完整代码 from ultralytics import YOLO model = YOLO('yolov8s.pt') # 直接传入文件夹路径,批量处理所有图片 results = model( source='batch_images', conf=0.3, save=True, project='runs/detect', name='my_batch_result', verbose=False ) # 统计总检测数量 total_objects = 0 for res in results: total_objects += len(res.boxes) print(f"批量处理完成,共处理图片{len(results)}张,总计检测目标{total_objects}个") print("所有标注结果图片保存在runs/detect/my_batch_result目录")运行后,程序会遍历文件夹内所有合法图片,逐张检测并保存标注结果,终端输出整体统计数据,适合数据集预处理、批量标注预览等场景。 五、新手必用核心参数说明 上面代码用到的参数,是日常推理最常用的几个,不需要记复杂文档,理解这几个就足够完成大部分测试任务: source:输入源,可以是单张图片路径、视频路径、文件夹路径、摄像头编号 conf:置信度阈值,范围0-1,数值越高,检测结果越严格,误检越少,但可能漏检小目标,新手常用0.25-0.5 save:布尔值,True为保存带框的结果文件,False为只计算不保存 project:结果保存的根目录,统一管理所有输出,避免文件混乱 name:单次推理的子文件夹名称,方便区分不同参数、不同模型的测试结果 verbose:True输出完整日志,False关闭冗余输出,只保留关键信息 这些参数可以自由组合,比如高置信度严格检测、指定自定义保存目录、批量处理加精简日志,适配不同使用场景。 六、本章常见问题与解决方法 视频运行报错,提示无法读取视频 原因:视频格式不兼容、文件损坏、路径包含中文或空格 解决:转换为mp4格式,重命名为纯英文无空格路径,检查文件是否可正常播放 批量处理只识别部分图片 原因:部分图片格式非JPG/PNG、文件名异常、图片损坏 解决:统一转换为JPG格式,删除无法打开的损坏图片,全部使用英文命名 CPU处理视频速度极慢,甚至卡顿 原因:视频分辨率过高、模型版本偏大、CPU性能有限 解决:换回yolov8n模型,压缩视频分辨率为720P及以下,缩短视频时长 输出目录找不到结果文件 原因:project和name参数理解错误,默认路径和自定义路径混淆 解决:固定使用runs/detect作为根目录,每次修改name区分任务,直接按路径层级查找 检测结果大量误检,出现无效目标 原因:置信度conf设置过低 解决:将conf从0.25提高到0.35-0.4,过滤低置信度无效目标 七、本章小结 这一章我们没有引入新的环境配置,完全基于上一章的运行环境,扩展了单图进阶、视频、批量图片三种核心推理方式,同时讲清楚了模型规格选择和新手必用参数。可以发现,YOLOv8的推理接口设计非常统一,无论输入源是图片、视频还是文件夹,核心代码结构完全不变,只需要修改source和少量配置参数。 现阶段不需要深入理解模型底层原理,先熟练掌握不同输入源的推理写法、参数调整,能稳定处理图片和视频,完成日常测试需求,就已经达到入门实战的标准。下一章我们会进入自定义数据的准备环节,学习使用标注工具制作自己的数据集,为训练专属检测模型做准备。
-
YOLOv8新手入门|半小时从0到1跑通目标检测 前言 最近想入门目标检测,选了YOLOv8——毕竟是现在最主流的版本,官方文档也算友好,但作为纯新手,光看文档还是踩了不少细节坑。今天把“从装环境到跑出第一个检测结果”的全过程拆解得明明白白,主打一个“新手跟着做就能成”,先不抠复杂理论,咱先把代码跑起来、看到效果再说。 ml1blk9f.png图片 一、环境搭建:新手别贪新,稳最重要 YOLOv8依赖Python和几个核心库,版本不对会踩大坑,我先把每一步的操作和验证方法写清楚,按步骤来绝对不出错。 1. 第一步:确认Python版本(重中之重) YOLOv8对Python版本有要求,太高的版本(比如3.11、3.12)会和依赖库不兼容,我亲测3.8、3.9、3.10这三个版本最稳,优先选3.9。 怎么查Python版本?打开电脑的终端(Windows叫命令提示符/PowerShell,Mac/Linux叫终端),输入: python --version # 或(部分电脑需要用python3) python3 --version回车后会显示版本号,比如“Python 3.9.18”就是合格的;如果显示3.11+,建议先装3.9版本(网上搜“Python3.9安装”,按系统步骤装就行,新手选“添加到PATH”,避免后续路径问题)。 2. 第二步:升级pip(避免安装库时出错) pip是Python装库的工具,旧版本容易装错包、出现兼容性问题,先升级到最新版: # Windows系统 python -m pip install --upgrade pip # Mac/Linux系统 python3 -m pip install --upgrade pipml1aj4tv.png图片 看到“Successfully upgraded pip”就说明升级成功了,耐心等几秒就行,过程很快。 3. 第三步:安装YOLOv8核心库ultralytics ultralytics是官方维护的YOLOv8库,不用复杂配置,一行命令就能安装: # Windows系统 pip install ultralytics # Mac/Linux系统 pip3 install ultralyticsml1aydce.png图片 安装过程中会自动下载依赖的库(比如numpy、opencv、pillow等),不用手动干预。看到“Successfully installed ultralytics-xxx”(xxx是版本号),就说明核心库装好了。 4. 第四步:安装PyTorch(最容易踩坑的一步) ultralytics必须依赖PyTorch才能运行,但直接用pip装可能会装到不匹配的版本,尤其是有显卡的同学,一定要按自己的系统和硬件选对命令,新手优先装CPU版,稳妥不出错。 先判断自己要不要装GPU版:如果你电脑是N卡(NVIDIA),且提前装了CUDA(新手如果没装CUDA,别折腾,先装CPU版,后续熟悉了再升级GPU);AMD显卡或没有独立显卡的,直接装CPU版即可。 安装命令(复制对应版本,粘贴到终端执行): ① CPU版(所有系统通用,新手首选): # Windows/Mac/Linux通用 pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpuml1azc1e.png图片 ② GPU版(仅NVIDIA显卡,需先装CUDA 11.8/12.1): 去PyTorch官网(https://pytorch.org/get-started/locally/),按提示选择系统、CUDA版本,复制生成的命令。比如Windows系统+CUDA 11.8,命令如下: pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118ml1azqvu.png图片 验证PyTorch是否装对(必做步骤):装完后,在终端输入python(或python3)进入Python交互模式,依次输入两行代码: import torch print(torch.cuda.is_available()) # 有GPU且装对会显示True,CPU版显示Falseml1b0u3d.png图片 如果没报错,就说明PyTorch装对了。输入exit()退出Python交互模式,进入下一步。 5. 最终验证:确认YOLOv8能正常导入 这一步能提前排查问题,避免后续写好代码白忙活。在终端输入python(或python3),输入: from ultralytics import YOLO print("YOLOv8环境搭建完成!")ml1b1s6y.png图片 没报错、能正常打印这句话,说明整个环境搭建完全没问题了,可以开始写代码跑demo了。 二、写6行代码,跑通第一个目标检测(全程不踩坑) 环境搭好,接下来就是最有成就感的环节——跑通第一个检测demo!我把代码逐行注释,新手照抄就行,连路径问题都帮你考虑到了。 1. 准备测试图片 ① 找一张包含常见物体的图片(比如有猫、狗、人、杯子、汽车的图),别用带中文的图片名,会报错,重命名为test.jpg; ② 把图片放在一个容易找到的文件夹里,比如Windows的“桌面/YOLO_test”,Mac的“文稿/YOLO_test”,后续代码和图片放同一文件夹,不用记复杂路径。 2. 编写核心代码(逐行解释,新手能懂) 打开记事本(Windows)或文本编辑(Mac),复制下面的代码,保存为detect_test.py(同样别用中文文件名),和test.jpg放在同一个文件夹里: # 1. 导入YOLO库(环境搭好才能正常导入,报错先查环境) from ultralytics import YOLO # 2. 加载YOLOv8预训练模型:选yolov8n(n代表nano,最轻量,运行最快,新手优先) # 第一次运行会自动下载yolov8n.pt模型文件,耐心等几秒(网络差可手动下载) model = YOLO('yolov8n.pt') # 3. 执行目标检测:传入图片路径,conf=0.25代表置信度(低于25%的目标不识别,避免误检) results = model('test.jpg', conf=0.25) # 4. 保存检测后的图片(自动画彩色框,标注目标名称和置信度) results[0].save('result.jpg') # 5. 打印检测结果:清晰显示识别到的目标和置信度 print("检测完成!以下是识别到的目标:") for box in results[0].boxes: # box.cls是目标类别编号,results[0].names是编号对应的类别名 class_name = results[0].names[int(box.cls)] # box.conf是置信度,保留两位小数,更易读 confidence = round(float(box.conf), 2) print(f"目标:{class_name},置信度:{confidence}")ml1bi7ts.png图片 有点不准(bushi) 3. 运行代码(两种方式,选一种就行) 方式1:终端运行(推荐,新手易排查问题) ① 打开终端,切换到图片和代码所在的文件夹: Windows系统(比如文件在桌面YOLO_test文件夹): cd Desktop/YOLO_testMac系统(比如文件在文稿YOLO_test文件夹): cd ~/Documents/YOLO_test② 输入运行命令,执行代码: # Windows系统 python detect_test.py # Mac/Linux系统 python3 detect_test.py方式2:用IDE运行(比如PyCharm、VS Code) ① 打开PyCharm/VS Code,导入存放代码和图片的文件夹; ② 右键点击detect_test.py文件,选择“Run”(运行),等待执行完成即可。 4. 查看检测结果(重点看这两个地方) ① 查看结果图片:文件夹里会多出result.jpg,打开后能看到图片上有彩色边框,边框旁标注了目标名称(比如cat、person、cup)和置信度,一目了然; ② 查看终端输出:终端会打印出识别到的目标和对应置信度,比如“目标:cat,置信度:0.92”,能清晰知道模型识别结果; 补充:如果没在文件夹根目录找到result.jpg,去runs/detect/predict目录找——这是YOLOv8默认的结果保存路径,第一次运行会自动生成这个文件夹,结果图一定在里面。 三、新手必看:我踩过的坑和解决方法 我第一次操作时,光环境搭建就耗了1小时,全是踩坑踩出来的经验,这几个坑新手大概率会遇到,提前记好解决方案: 1. 坑1:运行代码报“FileNotFoundError: test.jpg” 原因:图片路径错误,要么图片和代码不在同一文件夹,要么图片名写错(比如多打了空格、用了中文)。 解决:① 确认test.jpg和detect_test.py在同一文件夹;② 图片名必须是纯英文+后缀,无空格;③ 实在搞不定路径,就写绝对路径,比如Windows:model('C:/Users/你的用户名/Desktop/YOLO_test/test.jpg'),Mac:model('/Users/你的用户名/Documents/YOLO_test/test.jpg')。 2. 坑2:下载yolov8n.pt模型超时、失败 原因:网络问题,模型文件在国外服务器,国内网络下载容易卡顿超时。 解决:手动下载模型(网上搜“yolov8n.pt 官方下载”,从ultralytics官网或可信平台下载),把下载好的yolov8n.pt文件放到代码所在文件夹,代码会自动读取本地模型,不用再在线下载。 3. 坑3:导入YOLO时报“ImportError: Missing required dependencies ['torch']” 原因:PyTorch没装对,或版本不兼容,导致YOLO库无法调用。 解决:先卸载现有PyTorch,再重新安装。卸载命令:pip uninstall torch torchvision torchaudio,然后按前面的步骤重新装CPU版PyTorch,基本能解决。 4. 坑4:Mac运行报“OSError: dlopen(libtorch.dylib, 0x0006): Library not loaded” 原因:Mac系统Python环境混乱,库依赖路径不对。 解决:用Anaconda创建独立环境(新手搜“Anaconda安装教程”,很简单),创建Python3.9的环境后,在该环境下重新装ultralytics和PyTorch,就能避免路径冲突。 四、新手碎碎念 其实新手入门YOLOv8,最容易犯的错就是“追求新版本”“急于抠理论”——一开始我非要装Python3.12,结果各种兼容问题,换成3.9后瞬间顺畅;还总想着先搞懂“锚框”“特征提取”,越看越懵,反而打击积极性。 后来发现,先把代码跑起来、看到检测结果,有了成就感再回头补理论,效率会高很多。这篇教程主打“能跑就行”,把环境搭建、代码运行的每一步都拆碎,甚至把命令都写死,就是希望新手能少走弯路,快速get到目标检测的乐趣。 下一篇我会讲YOLOv8的拓展玩法——分割、姿态估计,其实就改一行代码的事,新手也能轻松上手,咱们下篇见。
-
HTML响应式天气预报网站源码_多端适配天气模板免费下载 HTML响应式天气预报网站源码 原生前端开发的多端适配天气网站搭建模板,无复杂部署与环境依赖,可直接用于快速搭建独立天气查询网站,也能无缝集成到现有站点作为功能模块,源码可扩展性强,适合前端开发二次定制开发。 ml0uvz1c.png图片 一、核心技术架构 基于前端原生技术栈开发,全程无后端服务、数据库依赖,开发和部署门槛极低,核心技术实现细节如下: 采用HTML5语义化标签构建页面结构,让代码可读性更强,同时适配搜索引擎抓取规则,兼顾基础SEO需求 以CSS3原生特性实现样式渲染,结合弹性布局、网格布局及媒体查询,打造全终端自适应的响应式布局,无需单独开发移动端、桌面端版本 原生JavaScript实现所有交互逻辑,包含异步API请求、数据解析渲染、城市选择交互、多城市数据管理等核心功能,无第三方框架冗余代码 基于AJAX/Fetch实现与公开天气API的对接,完成气象数据的异步获取与实时渲染,请求逻辑解耦,便于替换不同的天气数据接口 二、核心功能模块 功能覆盖天气查询的核心使用场景,模块划分清晰,交互逻辑简洁,所有功能均可直接使用或按需修改: 1. 城市天气精准查询 支持两种查询方式,一是手动输入城市名称快速检索,二是通过城市选择器分类选择,查询后实时渲染目标城市的核心气象数据,包含实时温度、空气湿度、风速、风向、天气状况等关键信息,数据展示直观无冗余。 2. 多日天气趋势预报 展示目标城市未来数日的气象趋势,按日期维度拆分,每个日期均展示最高温、最低温、实时天气状况,部分日期可展示时段性气象变化,满足用户提前规划出行的核心需求。 3. 多城市天气管理与对比 支持多城市添加、收藏与删除,可将常用城市加入收藏列表,收藏后多城市天气数据同屏展示,实现不同城市气象数据的直观对比,适配跨城市出行、异地生活等使用场景。 4. 天气状态可视化展示 所有天气状况均以图标化形式呈现,晴、雨、雪、雾、多云等状态对应专属视觉图标,搭配数值化的气象数据,让用户快速获取核心信息,视觉体验与使用体验兼顾。 三、源码核心优势 贴合前端开发的实际需求,从代码质量、使用体验、二次开发三个维度打造核心优势,适配个人开发、站点功能集成等多种场景: 代码质量高:无冗余代码、无无效嵌套,HTML、CSS、JS文件分离管理,变量与函数命名规范,注释简洁且仅标注核心逻辑,便于开发者快速理解代码结构 轻量且高效:原生开发无框架打包体积冗余,页面加载速度快,运行过程中无卡顿,在低配设备、弱网络环境下仍能保持流畅的使用体验 兼容性强:兼容Chrome、Firefox、Edge、Safari等所有主流浏览器,同时适配手机、平板、笔记本、台式机等全尺寸设备,无兼容适配问题 二次开发成本低:所有功能模块均做解耦处理,API请求、数据渲染、交互逻辑相互独立,可单独修改某一模块而不影响整体功能,支持按需增删、修改功能 四、二次开发拓展方向 基于现有源码结构,可快速拓展各类实用功能,无需重构核心代码,以下为贴合实际使用的拓展方向,均能基于原生前端技术实现: 新增空气质量监测模块,对接空气质量AQI接口,展示空气质量等级、PM2.5、PM10、臭氧等核心数据,标注空气质量适宜程度 加入生活气象指数,包含穿衣、出行、防晒、洗车、运动等实用指数,根据实时气象数据自动匹配推荐建议,提升网站实用性 实现自动定位功能,基于浏览器原生Geolocation获取用户所在位置,自动加载本地天气数据,减少用户手动操作步骤 新增气象预警功能,对接气象预警接口,实时展示暴雨、大风、高温、寒潮等气象预警信息,标注预警等级与影响范围 升级数据可视化效果,添加温度趋势折线图、湿度/风速柱状图,让气象数据的变化趋势更直观 增加个性化设置功能,支持背景随天气状态自动切换、摄氏度/华氏度单位切换、数据刷新时间自定义等 加入历史气象数据查询,支持按日期检索目标城市的历史气象信息,丰富网站数据维度 五、适用场景 个人开发者快速搭建专属的独立天气查询网站,或为自有站点集成天气查询功能模块,丰富站点功能 前端学习者作为原生JavaScript+HTML5+CSS3的实战学习案例,掌握响应式布局、异步API请求、前端交互逻辑的核心实现 小型站点快速上线配套的天气查询功能,无需投入大量开发成本,基于源码快速定制即可使用 下载 下载地址:https://pan.quark.cn/s/6491a56ac441 提取码:
-
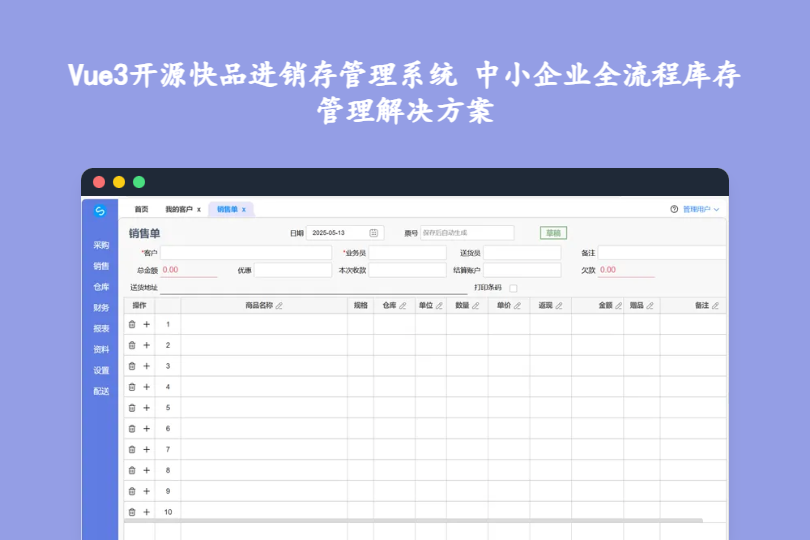
Vue3开源快品进销存管理系统 中小企业全流程库存管理解决方案 Vue3开源在线快品进销存管理系统源码:中小企业全流程库存管理解决方案 这款系统是基于Vue3+Node.js+Mssql构建的开源快消品进销存管理工具,以木兰宽松许可证第2版授权,主打全流程数字化管理,覆盖采购、销售、仓库、财务、配送五大核心环节,操作简便且拓展性强,专为中小企业快消品业务打造,大幅降低库存与运营管理成本。 mky8r438.png图片 一、核心技术架构:现代化栈,稳定高效 前端框架:采用Vue3开发,依托响应式编程与组件化设计优势,打造流畅易用的操作界面,支持多终端适配,不同屏幕尺寸下体验一致; 后端支撑:基于Node.js开发API接口,具备高并发处理能力,可稳定应对企业日常订单与库存数据的流转需求; 数据存储:选用Mssql数据库,支持复杂数据查询与事务处理,保障采购、销售、库存等核心数据的安全与准确; 授权与部署:遵循木兰宽松许可证第2版,可自由使用、修改与分发源码;支持本地服务器与云服务器部署,无需复杂配置即可上线。 二、核心功能模块:覆盖快消品进销存全流程 1. 采购管理 支持供应商信息管理,可维护供应商基本资料、联系方式与历史供货记录; 支持采购订单的创建、编辑、审核与跟踪,实现采购流程自动化; 采购入库时自动关联订单,同步更新库存数据,避免手动录入误差。 2. 销售管理 支持客户信息建档,涵盖客户基本资料、购买记录与信用额度设置; 支持销售订单的快速创建、修改、发货与退货操作,流程清晰可控; 销售出库时自动扣减对应商品库存,同步生成销售票据,便于财务对账。 3. 仓库管理 支持库存实时监控,可查看商品库存数量、存放位置与状态; 支持库存调拨、盘点与报废处理,帮助企业优化库存结构,减少商品积压; 支持多仓库、多货位管理,适配企业规模化仓储需求。 4. 财务管理 支持应收应付账款管理,跟踪销售回款与采购付款进度; 自动生成销售、采购、库存等多维度报表,为企业决策提供数据支撑; 支持商品成本、运输成本、仓储成本核算,助力企业精准控制运营成本。 5. 配送管理(特色功能) 可根据销售订单自动分配配送任务给对应配送员; 配送员可通过扫描销售票据二维码,快速完成出货核验; 支持配送状态实时跟踪,同步更新给客户,提升客户满意度。 三、源码核心特色 技术先进,体验流畅 基于Vue3+Node.js技术栈开发,系统性能稳定且可扩展性强;响应式设计适配多设备,操作流程简洁,降低员工学习门槛。 功能全面,流程闭环 覆盖从采购入库到销售出库、财务核算、物流配送的全流程管理,实现快消品业务的数字化闭环,提升运营效率。 易于集成,灵活定制 采用模块化设计,可根据企业需求新增功能模块;开放API接口,支持与ERP、CRM等其他企业系统集成。 开源免费,成本可控 遵循木兰宽松许可证第2版,企业可免费使用、修改源码,无需支付软件授权费用,大幅降低信息化建设成本。 四、适用场景 快消品中小企业:如零食、饮料、日用品批发商与零售商,用于管理库存、订单与配送业务; 创业团队:低成本搭建进销存管理系统,快速实现业务数字化; 技术开发团队:作为Vue3+Node.js实战项目,学习进销存系统架构设计,或基于源码定制化开发行业专属方案。 下载 下载 下载地址:https://pan.quark.cn/s/7a6eb3cea7cc 提取码:
-
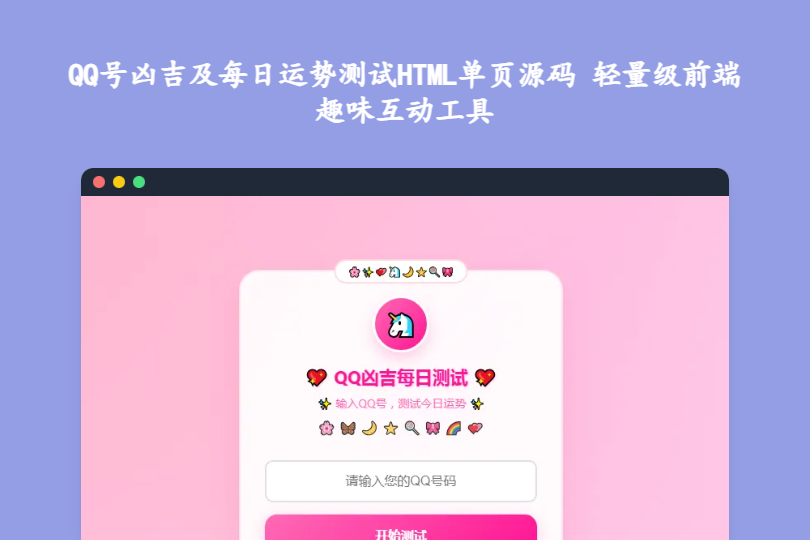
QQ号凶吉及每日运势测试HTML单页源码 轻量级前端趣味互动工具 QQ号凶吉及每日运势测试HTML单页源码:轻量级前端趣味互动工具 这款QQ号凶吉及每日运势测试HTML单页源码,是基于HTML+CSS+JavaScript开发的轻量级趣味网页应用,无需后端支持和数据库存储,所有功能均通过前端技术实现。它主打QQ号凶吉测算与每日运势预测两大核心功能,适配多终端访问,易于部署和二次开发,适合嵌入个人博客、趣味网站或用于社交媒体分享,为用户提供轻松有趣的互动体验。 mkwn5s3t.png图片 一、核心技术与基础特性 开发技术:完全基于HTML+CSS+JavaScript原生开发,无任何第三方库依赖,代码结构清晰,注释详尽 源码规格:源码大小仅4.1KB,单页设计,页面加载速度快,运行流畅无冗余 部署条件:无需复杂环境配置,可直接部署到任意支持静态网页的服务器、云存储静态托管平台 更新时间:2025年6月13日更新,适配主流浏览器与多终端显示需求 二、核心功能模块:趣味互动+便捷操作 1. QQ号凶吉测试 用户输入QQ号码后,系统根据预设算法自动计算并输出该QQ号的凶吉指数,满足用户的好奇心与娱乐需求。 2. 每日运势预测 结合用户输入的QQ号与当日日期,生成专属的每日运势信息,结果带有随机性,每次刷新都能带来不同体验。 3. 动态交互与适配 采用响应式设计,自动适配电脑、手机、平板等不同屏幕尺寸的设备,保障多终端访问体验一致 内置按钮点击反馈、表单验证功能,确保用户输入操作的友好性和准确性,避免无效提交 4. 高度可拓展 开发者可自由调整核心算法逻辑,比如修改QQ号凶吉的计算规则,或优化每日运势的生成方式,满足个性化定制需求 三、源码核心特色:低门槛+高灵活 简单易用,部署便捷 无需后端开发和数据库维护,所有数据处理均在前端完成,降低部署和运营门槛,新手也能快速上线使用 趣味性强,互动性高 以QQ号为切入点结合运势预测,精准契合用户的娱乐需求,随机化的测试结果能提升用户的重复访问意愿 灵活定制,个性调整 支持自由修改页面样式、字体颜色、背景图片等视觉元素,同时可根据目标用户群体调整运势内容和测算规则 跨平台兼容,使用广泛 基于标准Web技术开发,兼容Chrome、Firefox、Safari等主流浏览器,支持移动端便捷访问,不受设备限制 四、适用场景:精准匹配多样化需求 个人博客/趣味网站:嵌入页面作为互动功能,提升网站趣味性和用户停留时长 社交媒体分享:生成趣味测试链接分享,借助社交裂变吸引流量 前端开发学习:作为HTML+CSS+JavaScript前端实战案例,学习单页应用开发与交互逻辑设计 小型营销活动:作为引流工具,为公众号、小程序等平台吸引粉丝关注 下载 下载 下载地址:https://pan.quark.cn/s/19690bab5f92 提取码:
-
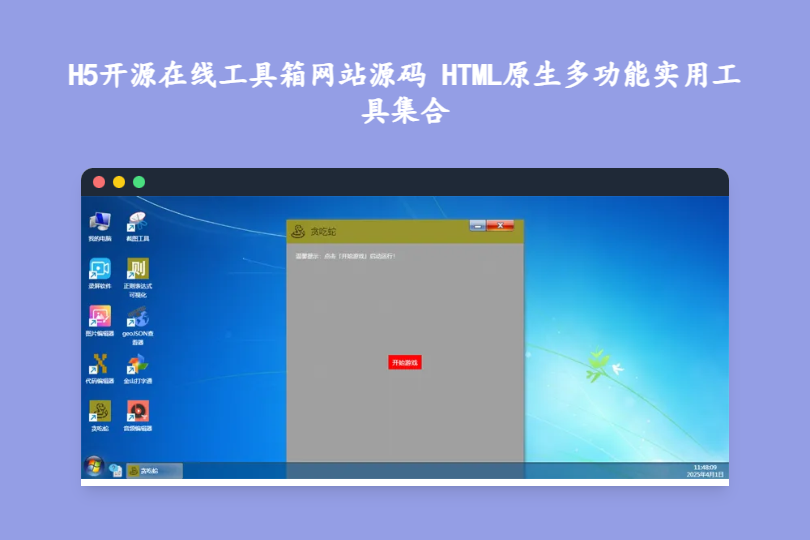
H5开源在线工具箱网站源码 HTML原生多功能实用工具集合 H5开源在线工具箱网站源码:HTML原生开发的多场景实用工具集合 这款H5开源在线工具箱网站源码,是基于HTML+CSS+JavaScript浏览器原生开发的轻量级工具集合,无任何第三方库依赖,既保证了运行高效性,又降低了二次开发门槛。源码包含多款实用工具与趣味功能,支持多设备自适应访问,适合个人搭建在线工具平台、开发者学习原生前端开发,或嵌入现有网站丰富功能,开源免费且易于部署维护。 mkwconwo.png图片 一、核心技术与基础信息 1. 技术架构明细 模块具体内容核心优势开发语言HTML + CSS + JavaScript(原生开发)无第三方库依赖,代码简洁易懂,便于修改与拓展,轻量化运行不占用过多资源源码特性自定义打包工具、无冗余组件开发者可按需调整打包逻辑,优化功能模块,避免冗余代码影响加载速度 部署支持静态部署、云平台托管无需复杂环境配置,打包后即可上传上线,新手也能快速完成搭建二、核心功能模块:实用工具+趣味互动 1. 高效办公工具 代码编辑器:支持图片、代码的查看与编辑,可打开、新建、编辑、保存文件或目录,满足轻量级代码编写与查看需求; 图片编辑器:提供图片合并、尺寸修改、美化等功能,无需安装本地软件,在线即可完成简单图片处理; 录屏软件:H5原生开发的电脑屏幕录制工具,操作便捷,可快速录制屏幕操作并保存,适配日常办公演示、教程制作场景; 正则表达式可视化:输入正则表达式后自动生成可视化图表,帮助快速理解正则逻辑,降低学习与使用门槛; 音频编辑器:支持多种格式音频文件的切割、合并操作,在线完成音频剪辑,无需专业剪辑软件。 2. 趣味与辅助功能 内置贪吃蛇、金山打字通等趣味工具,兼顾实用性与娱乐性,丰富平台使用场景; 包含geoJSON查看器,适配地理数据查看需求,满足特定行业用户使用。 三、源码核心特色:差异化优势凸显 原生开发,轻量化高效:基于浏览器原生技术构建,无第三方依赖,页面加载速度快,运行流畅,适配低配置设备与弱网环境; 多设备自适应:自动检测访问设备(手机、电脑),调整界面布局与交互方式,保障不同终端下的使用体验一致; 易拓展易修改:代码结构清晰,自定义打包工具支持功能模块调整,开发者可新增工具、修改现有功能,快速适配个性化需求; 开源免费,无捆绑限制:完全开源允许自由修改与商业使用,无隐藏功能限制,个人与企业均可免费部署使用; 开发学习价值高:原生前端开发案例完整,包含多种工具的实现逻辑,适合前端开发者学习HTML、CSS、JavaScript原生应用开发。 四、开发与部署步骤 1. 本地开发流程 克隆项目源码至本地后,执行命令启动开发服务器:npm run dev; 启动成功后,在浏览器访问 http://127.0.0.1:20000/ 即可预览应用,实时调试功能; 开发完成后,执行打包命令:npm run build,生成可部署的静态文件。 2. 部署方式 静态部署:将打包后的文件上传至虚拟主机、云存储静态托管(如阿里云OSS、腾讯云COS),直接绑定域名即可访问; 云平台部署:支持各类静态网站托管平台一键部署,无需额外配置服务器环境,快速上线。 五、适用场景:精准匹配不同需求 个人用户:搭建专属在线工具平台,整合日常所需的图片处理、正则验证、录屏等功能,摆脱多软件安装困扰; 前端开发者:作为原生HTML/CSS/JS实战项目,学习工具类应用开发逻辑,或基于源码二次开发,新增天气查询、文本处理等自定义工具; 企业/站长:将工具箱嵌入现有网站(如博客、社区),丰富平台功能,提升用户停留时长与活跃度; 教育场景:作为前端教学案例,帮助学员理解原生技术的实际应用,培养功能开发与代码优化能力。 下载 下载 下载地址:https://pan.quark.cn/s/982e3373505a 提取码:
-
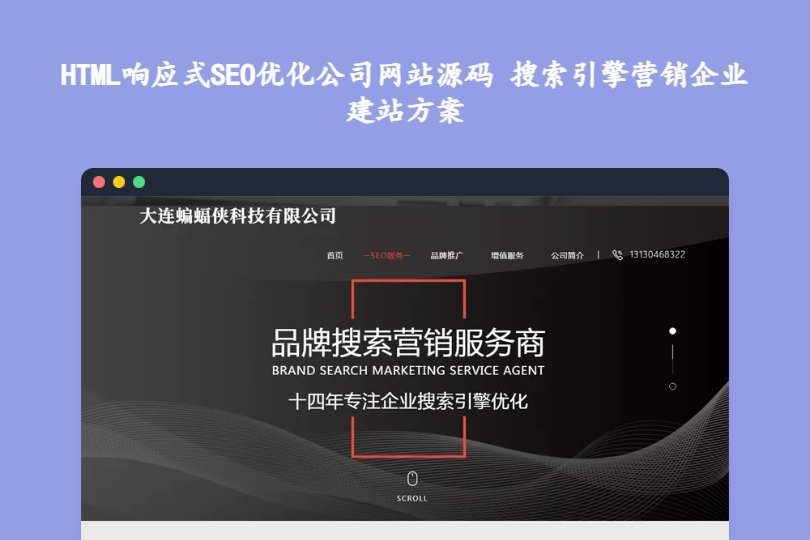
HTML响应式SEO优化公司网站源码 搜索引擎营销企业建站方案 HTML响应式SEO优化公司网站源码:搜索引擎营销企业专属建站方案 这款HTML响应式SEO排名优化公司网站源码,是专为搜索引擎营销、SEO服务类企业打造的建站解决方案。基于HTML+CSS技术构建,以“响应式适配+SEO友好+模块化设计”为核心,预设完整的企业展示与服务推广页面,无需复杂开发即可快速搭建美观、高效的品牌官网,助力SEO公司、搜索营销服务商展示业务优势与品牌实力。 mkv5rlik.png图片 一、核心技术与基础特性 技术架构:采用纯HTML+CSS开发,无需复杂后端依赖,无特定数据库要求,源码体积仅1.5MB,加载速度快,部署门槛极低,普通虚拟主机即可稳定运行; 响应式布局:自动适配桌面电脑、平板电脑、智能手机等不同设备屏幕,无论用户通过何种终端访问,都能获得清晰、流畅的浏览体验,契合移动搜索流量趋势; 跨浏览器兼容:全面支持Chrome、Firefox、Safari、Edge等主流浏览器,避免因浏览器差异导致的页面错乱,保障所有访客的访问体验一致; 更新与维护:2025年1月13日更新优化,模块化结构设计让内容维护更便捷,非技术人员也能快速修改页面信息、替换素材。 二、核心功能模块:覆盖SEO营销公司全场景需求 1. 预设完整企业页面体系 核心页面包含首页、关于我们(公司简介、发展历程)、服务展示(搜索营销、品牌营销、SEO排名优化、SEO顾问)、新闻动态、联系我们等,无需额外开发即可满足企业基础展示需求; 服务展示页面针对性适配SEO行业特性,可详细呈现业务范围:如搜索引擎排名优化、品牌搜索营销、SEO诊断分析、口碑推广、百家号运营、问答平台营销、新闻软文发布、新媒体运营等,清晰传递核心服务价值。 2. 优化型设计:兼顾美观与SEO效果 视觉设计:提供多款精美预设模板,页面布局简洁大方,重点突出服务优势与企业实力,搭配专业配色与排版,提升品牌专业度; SEO友好设计:页面结构符合搜索引擎抓取规则,支持自定义页面标题、关键词、描述,优化页面加载速度,助力官网在搜索结果中获得更好排名,契合SEO公司自身建站的核心诉求。 3. 实用运营功能:易维护、高适配 模块化内容管理:采用模块化设计,企业可自由组合页面内容,快速更新服务介绍、新闻资讯、联系方式等信息,无需修改核心代码; 快速加载优化:优化页面资源加载逻辑,减少冗余代码与素材体积,提升页面打开速度,既改善用户体验,也符合搜索引擎对加载速度的评分标准; 品牌展示适配:支持展示企业资质、案例成果、团队介绍、合作伙伴等内容,助力SEO营销公司全方位展现业务实力与行业积累,增强客户信任度。 三、核心特色:SEO营销企业的差异化建站优势 行业针对性强:预设SEO、搜索营销相关服务页面与内容框架,无需从零设计,直接适配搜索引擎营销公司的业务展示需求; 响应式+SEO双核心:既解决多终端访问适配问题,又通过SEO友好设计助力官网自身排名提升,完美契合SEO公司的建站核心诉求; 轻量化易部署:纯HTML静态架构,源码体积小,部署简单,无需专业技术团队维护,节省企业建站与运营成本; 美观易定制:多款精美模板可选,模块化结构支持灵活调整页面内容与布局,可快速打造符合品牌调性的专属官网。 四、适用场景:精准匹配目标用户 SEO服务公司/搜索引擎营销服务商:快速搭建官网,展示SEO排名优化、品牌营销、口碑推广等核心业务,吸引潜在企业客户; 网络营销工作室/初创型营销企业:低成本搭建专业品牌官网,无需投入大量开发资源,快速实现线上品牌曝光与业务承接; 传统企业转型线上营销:搭建聚焦SEO与搜索营销的业务展示网站,突出线上推广服务优势,拓展企业服务范围。 下载 下载 下载地址:https://pan.quark.cn/s/cf27a36ed75e 提取码:
-
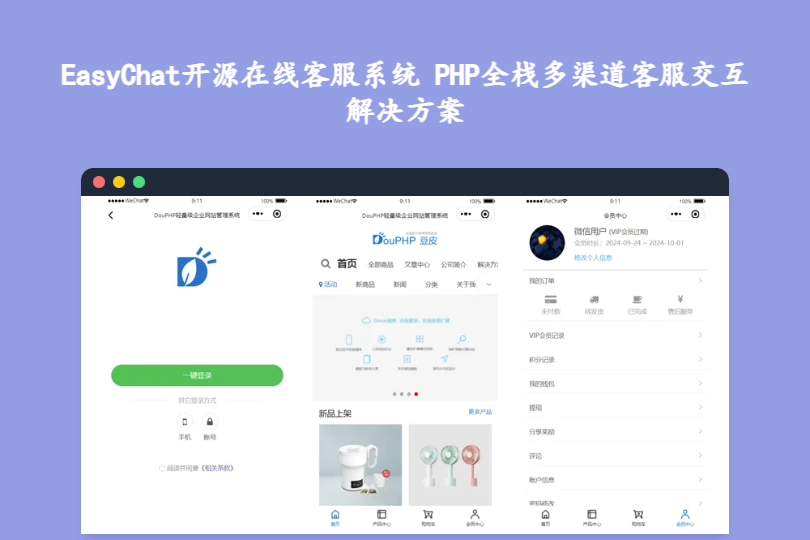
EasyChat开源在线客服系统 PHP全栈多渠道客服交互解决方案 EasyChat开源在线客服系统:PHP全栈多渠道客服交互解决方案 EasyChat是一款基于PHP开发的开源在线客服系统,聚焦企业全渠道客户沟通需求,支持网页端、移动端、小程序等多终端接入,实现客户咨询、消息应答、工单管理的全流程闭环。系统采用轻量化架构设计,适配中小企业快速部署,同时具备灵活的二次开发能力,既适合电商、教育、企业服务等行业搭建专属客服体系,也能满足开发者学习PHP客服系统开发的实战需求。 mktn72tn.png图片 一、技术架构:轻量化设计,多端适配 系统依托PHP主流技术栈搭建,兼顾运行稳定性与操作易用性,大幅降低企业部署与维护门槛: 后端核心:基于PHP + MySQL开发,采用轻量级MVC架构,代码结构清晰易懂,普通虚拟主机即可稳定运行,无需高配置服务器支撑; 前端适配:客服端与访客端均采用响应式设计,兼容PC网页端、移动端H5、微信小程序等多终端,不同设备下交互体验一致; 通信机制:基于WebSocket实现实时消息推送,保障客服与访客之间的即时沟通,无延迟、无卡顿,提升客户咨询体验; 部署支持:兼容Windows、Linux服务器系统,支持宝塔面板一键部署,无需专业技术背景,新手也能快速完成系统搭建。 二、核心功能模块:覆盖客服运营全场景 系统功能围绕“高效沟通-工单管理-数据复盘”的客服业务逻辑设计,精准满足企业客户服务的核心需求: 1. 多渠道沟通:统一接入,高效应答 全渠道整合:网页在线咨询、移动端H5客服、小程序客服等多渠道访客咨询统一接入客服工作台,客服无需切换多个平台,减少操作成本; 实时消息交互:访客无需注册即可发起咨询,支持文字、图片、表情等消息类型,客服端实时接收消息提醒,支持快捷回复、消息转发,提升应答效率; 访客信息识别:自动获取访客IP、访问页面、设备类型等基础信息,客服可快速了解访客来源与需求,精准应答咨询问题。 2. 工单管理:闭环处理,跟踪到底 工单创建与分配:客服可将复杂咨询、售后问题转为工单,按业务类型分类,并支持自动/手动分配给对应岗位的客服人员; 工单状态跟踪:支持工单“待处理-处理中-已解决-已关闭”全状态流转,后台可实时查看工单进度,避免客户问题遗漏; 工单统计:自动统计各类型工单数量、处理时长、解决率,为优化客服流程提供数据支撑。 3. 客服管理:精细化运营,提升效率 客服账号管理:支持多客服账号创建,按部门、岗位分配不同权限,客服主管可查看所有客服的接待数据,便于团队管理; 快捷回复库:支持创建行业化、场景化的快捷回复模板,客服可一键调用,减少重复输入,提升应答速度; 会话记录管理:自动保存所有沟通记录,支持按时间、访客信息、客服账号等维度检索,方便后续复盘与问题追溯。 4. 数据统计与分析:量化客服效能 核心数据看板:实时展示客服接待量、响应时长、会话结束率、工单解决率等核心指标,直观呈现客服团队工作效率; 访客分析:统计访客来源渠道、咨询热点问题、转化率等数据,帮助企业了解客户需求,优化产品与服务; 报表导出:支持将统计数据导出为Excel格式,便于企业进行月度、季度的客服效能复盘与汇报。 三、核心特色:适配中小企业的客服解决方案 开源免费,成本可控:遵循MIT开源协议,源码完全开放,无隐藏费用与功能限制,企业可免费部署使用,大幅降低客服系统搭建成本; 轻量化易部署:普通虚拟主机即可运行,宝塔面板一键部署,无需专业技术团队维护,中小企业可快速上线使用; 实时交互体验佳:基于WebSocket的实时通信机制,消息推送无延迟,客服与访客沟通流畅,提升客户满意度; 拓展性强:代码结构模块化,支持新增渠道接入、自定义快捷回复模板、对接企业CRM系统,满足个性化运营需求。 四、适用场景:精准匹配不同行业需求 电商行业:搭建专属在线客服体系,处理售前咨询、订单售后、物流查询等问题,提升客户购物体验; 教育培训机构:解答课程咨询、报名流程、学习问题等,通过工单管理跟踪学员售后问题,优化服务流程; 企业服务/SAAS行业:处理客户产品使用咨询、技术支持问题,通过数据统计分析客户咨询热点,迭代产品功能; 中小企业/初创团队:以低成本搭建客服体系,无需依赖第三方付费客服工具,实现客户咨询的全流程管理。 下载 EasyChat下载 下载地址:https://pan.quark.cn/s/9f2b90c8d877 提取码: 总结 EasyChat基于PHP+MySQL开发,采用WebSocket实现实时消息交互,轻量化架构适配中小企业快速部署; 核心功能覆盖多渠道沟通、工单管理、客服权限管控、数据统计,满足客服运营全流程需求; 开源免费且拓展性强,可适配电商、教育等多行业,大幅降低企业客服系统搭建成本。
-
CVE-2026-24061漏洞修复教程:Linux服务器root权限绕过应急方案 CVE-2026-24061漏洞紧急预警:Linux服务器root权限秒破?手把手教你全流程修复与防护 0.jpeg图片 近日,GNU InetUtils组件曝出高危漏洞CVE-2026-24061,CVSS评分高达9.8分,属于“无需凭证、一键提权”的致命漏洞。该漏洞可让攻击者通过构造恶意环境变量,直接绕过身份验证获取Linux服务器root权限,互联网上超900万台暴露23端口的设备面临直接威胁。本文将从漏洞原理、影响范围、应急修复、入侵排查到长效防护,为运维及安全从业者提供完整解决方案。 一、漏洞核心信息速览 漏洞编号:CVE-2026-24061 危险等级:严重(CVSS 9.8) 影响组件:GNU InetUtils中的telnetd服务 受影响版本:inetutils 1.9.3 至 2.7 版本(含两端) 漏洞本质:参数注入(CWE-88),未对环境变量输入做校验导致认证绕过 利用难度:极低,仅需构造1个恶意参数即可成功提权 二、漏洞原理深度剖析 GNU InetUtils是类UNIX系统常用的网络工具集,其中telnetd作为telnet协议的服务端实现,负责处理远程登录请求。本次漏洞的根源在于telnetd对用户环境变量的不当处理: telnetd的login调用模板中,存在 PATH_LOGIN "-p -h %h %?u{-f %u}{%U}" 格式定义,其中%U变量对应USER环境变量的值; telnetd/utility.c中的_var_short_name()函数在解析%U变量时,直接返回getenv("USER")的原始值,未做任何过滤校验; 攻击者向USER环境变量注入 -f root 参数,telnetd会将该值直接传递给login程序; login程序将“-f”识别为“跳过密码认证”选项,直接以root身份登录系统,实现无凭证提权。 注意:Ubuntu/CentOS系统默认telnetd为netkit实现,而非InetUtils版本,仅手动安装过GNU InetUtils telnetd的设备会受影响。 三、应急修复步骤(优先级:最高) 漏洞已公开且利用门槛极低,建议立即执行以下操作,优先阻断攻击路径: 步骤1:升级inetutils至安全版本(核心修复) 目前官方已推出修复版本,需将inetutils升级至2.7以上(各发行版apt/yum仓库已推送补丁),不同系统操作如下: Debian/Ubuntu系(apt包管理器) # 更新软件源缓存 sudo apt update # 升级inetutils组件 sudo apt upgrade inetutils -y # 验证版本(需显示≥2.7) dpkg -l inetutils | grep inetutils # 重启inetd服务(若使用inetd管理telnetd) sudo systemctl restart inetdCentOS/RHEL系(yum包管理器) # 升级inetutils组件 sudo yum update inetutils -y # 验证版本(需显示≥2.7) rpm -q inetutils步骤2:禁用telnetd服务(阻断利用入口) 无论是否升级,建议直接禁用telnetd服务(telnet协议本身明文传输,安全性极差): # 立即停止并永久禁用telnetd sudo systemctl disable --now telnetd # 额外禁用telnet.socket(部分系统依赖) sudo systemctl disable --now telnet.socket # 验证状态(需显示inactive) systemctl status telnetd步骤3:关闭23端口(双重防护) telnet默认使用23端口,通过防火墙阻断该端口流量,进一步降低风险: firewalld防火墙(主流系统默认) # 永久阻断23端口入站流量 sudo firewall-cmd --permanent --remove-port=23/tcp # 重载防火墙规则 sudo firewall-cmd --reload # 验证(无输出则表示已阻断) firewall-cmd --list-ports | grep 23iptables防火墙(传统系统) # 阻断23端口入站流量 sudo iptables -A INPUT -p tcp --dport 23 -j DROP # 保存规则(避免重启失效) sudo service iptables save四、入侵痕迹排查(关键操作) 修复后需立即排查服务器是否已被入侵,重点检查以下日志及特征: 1. 登录日志分析 Linux系统登录记录主要存储在 /var/log/auth.log(Debian/Ubuntu)或 /var/log/secure(CentOS/RHEL),执行以下命令筛选异常: # 查找无密码root登录记录 grep -E "root|LOGIN" /var/log/auth.log | grep -v "password" # 查找telnet相关登录记录 grep "telnet" /var/log/auth.log # 筛选异常时间(如凌晨2-5点非工作时间登录) grep "Jan 2[0-3]" /var/log/auth.log | grep "root"2. 异常特征排查 进程检查:查看是否有未知进程,尤其是/tmp、/var/tmp目录下的异常进程(ps aux | grep -v grep | grep "/tmp"); 计划任务:检查crontab是否有恶意定时任务(crontab -l、ls /etc/cron.d/); 账号异常:排查是否新增隐藏账号(cat /etc/passwd | grep -v nologin); 网络连接:查看是否有异常出站连接(netstat -antp | grep ESTABLISHED)。 进阶建议:使用ELK Stack、Splunk等工具统一分析日志,快速定位异常IP及行为。 五、长效防护方案 淘汰不安全协议:彻底禁用telnet,改用SSH(22端口)进行远程管理,SSH需关闭密码登录,仅启用密钥认证; 组件版本管控:定期更新系统及依赖组件,建立版本台账,对高危组件(如inetutils、openssl)开启自动更新提醒; 端口最小化暴露:仅开放业务必需端口,通过防火墙、安全组限制访问来源IP,避免23、21等高危端口暴露在公网; 日志常态化审计:留存至少6个月系统日志,重点监控root登录、权限变更、服务启停等行为,建立异常告警机制; 漏洞生命周期管理:关注CVE公告及厂商预警(如GNU官方、国内安全厂商通告),高危漏洞修复周期不超过24小时。 六、常见问题解答(FAQ) Q1:我的服务器没装telnet,还需要修复吗? A1:无需修复。仅安装并启用了GNU InetUtils telnetd的设备受影响,默认未安装telnet服务的服务器无风险。 Q2:升级inetutils后,还需要禁用telnetd吗? A2:建议禁用。telnet协议明文传输数据,即使修复漏洞,仍存在账号密码泄露风险,优先使用SSH。 Q3:如何确认服务器使用的是哪种telnetd实现? A3:执行 telnetd -V,若输出“GNU inetutils”则为受影响版本,若为“netkit”则无需担心。
-
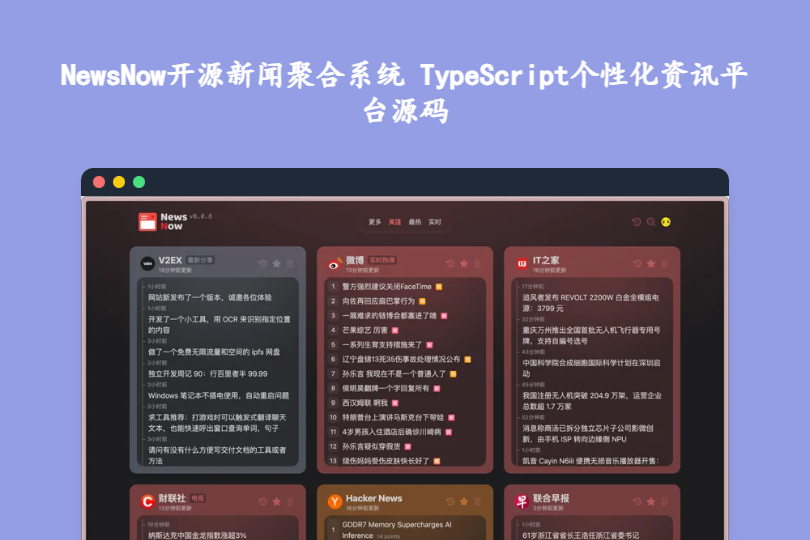
NewsNow开源新闻聚合系统 TypeScript个性化资讯平台源码 NewsNow开源新闻聚合系统:TypeScript打造的个性化资讯平台(v0.0.24版) NewsNow是一款基于TypeScript开发的开源个性化新闻聚合网站源码,主打简洁界面与流畅阅读体验,通过智能爬虫整合多源资讯,支持个性化定制与多端数据同步,部署方式灵活多样,无论是个人搭建专属资讯入口,还是开发者学习TypeScript实战,都能高效适配,在GitHub上拥有较高关注度与活跃社区支持。 mkowhz3r.png图片 一、核心技术架构:轻量灵活,多场景适配 1. 技术栈与部署支持 模块具体内容核心优势开发语言TypeScript(基于JavaScript)类型安全保障,代码结构清晰,便于维护与二次开发,适配现代Web开发需求部署方式Docker、Cloudflare Pages、Vercel支持多种主流部署平台,无需复杂环境配置,个人与企业均可快速上线数据存储无特定数据库依赖(适配多种存储方案)轻量化设计,降低部署门槛,可根据需求灵活选择存储方式包管理器推荐pnpm安装速度快,依赖管理高效,减少项目体积与冲突概率认证方式GitHub OAuth快速实现用户登录与数据同步,无需单独搭建账号体系,提升用户使用便捷性二、核心功能模块:聚焦资讯聚合与个性化体验 1. 实时新闻聚合与智能排序 依托智能爬虫技术,从IT之家、微博热搜、财联社、联合早报等多个主流新闻源抓取实时资讯,覆盖科技、财经、社会、娱乐等多领域; 通过内置算法对新闻进行排序,优先展示热门、最新内容,同时过滤重复资讯,确保展示内容的时效性与唯一性; 新闻展示界面简洁大方,无冗余广告,聚焦阅读体验,支持快速浏览标题与详情跳转。 2. 个性化定制与兴趣匹配 用户可根据自身兴趣选择关注的新闻源(如仅订阅IT之家、Hacker News)与内容类别(如科技、财经),系统精准推送契合的资讯; 支持自定义阅读偏好,调整新闻展示密度、排序规则,打造专属阅读界面,适配不同用户的使用习惯。 3. 跨设备数据同步 支持GitHub账号登录,用户的关注列表、阅读进度、定制偏好等数据可实时同步,在电脑、手机、平板等不同设备间切换时,保持体验一致性; 登录用户可手动强制拉取最新资讯,突破默认缓存限制,及时获取关键信息。 4. 智能缓存与爬虫策略 默认设置30分钟缓存周期,减少重复爬取,提升页面加载速度,同时降低服务器资源消耗; 针对不同新闻源的更新频率,自动调整爬虫间隔时间,避免频繁爬取导致IP封禁,保障数据抓取的稳定性与合规性。 三、源码核心特色:差异化优势凸显 1. 阅读体验优质 界面设计简洁优雅,无多余干扰元素,排版清晰,适配不同屏幕尺寸,长时间阅读不易疲劳,满足用户“高效获取资讯”的核心需求。 2. 灵活性与扩展性强 部署方式多样化,可根据自身资源选择Docker容器化部署、Cloudflare Pages/Vercel等静态托管平台部署,无需专业服务器; 源码结构清晰,模块化设计便于功能扩展,开发者可新增新闻源、优化推荐算法、添加评论互动等功能。 3. 开源免费且社区活跃 遵循MIT开源许可协议,源码完全开放,无商业捆绑与功能限制,支持自由修改与二次开发; GitHub社区关注度高,开发者可反馈问题、提交功能建议,获取及时的技术支持与版本更新。 4. 轻量化易上手 源码大小仅2.3MB,资源占用低,部署与维护成本低,即使是非专业技术人员,跟随文档步骤也能快速完成搭建。 四、安装与部署步骤(本地开发环境) 本站提供压缩包,不会拉库的可以直接下载 下载 下载地址:https://pan.quark.cn/s/341e17d90c4e 提取码: 1. 克隆项目源码 打开终端或命令提示符,执行以下命令克隆GitHub仓库至本地: git clone https://github.com/ourongxing/newsnow.git && cd newsnow2. 安装依赖包 先确保已安装pnpm包管理器(未安装可先执行npm install -g pnpm),再在项目目录下运行: pnpm install3. 配置环境变量 在项目根目录找到example.env.server文件,重命名为.env.server; 根据需求配置环境变量,核心需设置GitHub OAuth应用的Client ID与Client Secret,确保登录与数据同步功能正常。 4. 启动开发服务器 执行以下命令启动本地开发服务器: pnpm dev启动成功后,在浏览器访问http://localhost:3000(默认端口,可在.env.server中修改)即可预览应用。 5. 生产环境部署 支持Docker、Cloudflare Pages、Vercel等多种部署方式,具体步骤可参考项目官方文档或对应平台的部署指南,流程简单且无需复杂配置。 五、适用场景:精准匹配不同需求 1. 开发者/技术学习者 作为TypeScript实战项目,可学习智能爬虫、数据聚合、跨设备同步等核心功能的实现逻辑; 基于源码二次开发,拓展功能或优化架构,积累Web开发实战经验。 2. 个人用户 搭建专属新闻聚合平台,过滤冗余广告与无关资讯,仅获取关注领域的精准内容,提升资讯获取效率; 跨设备同步阅读进度,适配通勤、办公等碎片化场景,随时掌握最新动态。 3. 小团队/自媒体 快速搭建行业资讯门户,聚合垂直领域新闻源,为团队或粉丝提供集中的资讯获取渠道; 无需投入大量开发成本,借助开源源码快速上线,后续可根据需求逐步定制化优化。
-
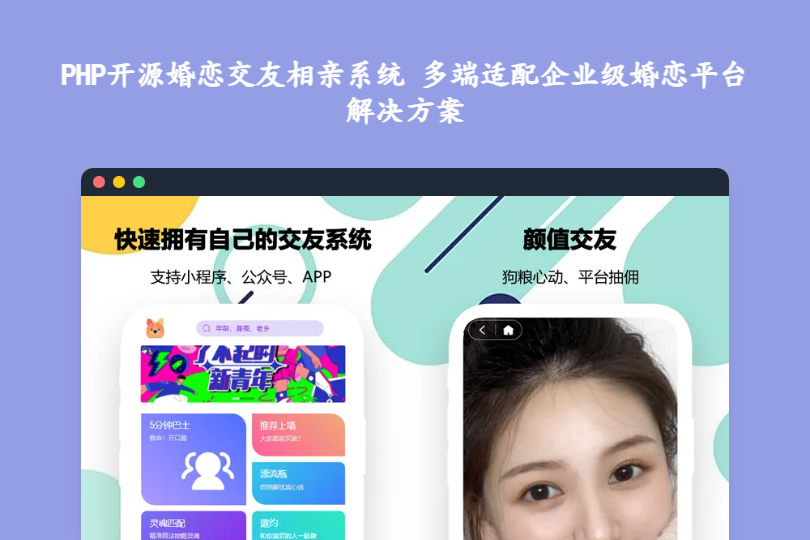
PHP开源婚恋交友相亲系统 多端适配企业级婚恋平台解决方案 PHP开源婚恋交友相亲系统:多端适配的企业级婚恋平台解决方案 这款基于THINKPHP6与uni-app构建的PHP开源婚恋交友相亲系统,是专为婚恋行业打造的全流程运营解决方案,无需重复开发即可覆盖微信小程序、H5、APP、公众号等多端场景。从用户真实认证、智能匹配,到社交互动、商业变现,系统搭建起完整的婚恋业务闭环,既适配婚介机构线下线上一体化运营,也能满足创业者快速搭建区域化、垂直类婚恋平台的需求,开源无捆绑限制,技术架构稳定且拓展性强。 mkng0lpa.png图片 一、技术架构:轻量高效,多端协同 系统采用前后端分离的现代化架构设计,兼顾运行效率与适配灵活性,能适配不同规模的运营场景: 后端核心:基于THINKPHP6框架开发,模块化设计让功能拓展更便捷,轻量高效的特性保障高并发场景下系统稳定运行,同时提供完整的API接口体系,可轻松对接第三方工具或进行二次开发; 前端适配:依托uni-app框架实现“一套代码多端部署”,可直接编译为微信小程序、H5、iOS/Android APP,无需为不同终端单独开发,大幅降低后期维护成本;界面设计兼顾不同年龄段用户的操作习惯,简洁易上手; 多端联动逻辑:公众号用于活动推送、匹配提醒等用户触达场景,小程序与H5满足用户轻量化使用需求(快速登录、浏览匹配对象),APP则承载深度互动功能(实时聊天、圈子动态、线下活动报名),形成全场景用户覆盖。 二、核心功能模块:覆盖婚恋平台全运营场景 系统功能围绕“真实匹配-互动沉淀-盈利转化”的核心逻辑设计,每个模块精准贴合婚恋行业的运营需求: 1. 用户管理:精细化运营,筑牢真实交友基础 会员资料体系:支持用户完善多维度资料,包括基本信息、语音自我介绍、分类相册等,后台可对资料进行真实性审核,过滤虚假信息;同时支持按地域、年龄、择偶偏好等维度筛选用户,提升匹配精准度; 虚拟币管理:内置专属虚拟币体系,可用于购买匹配机会、打赏互动、付费进圈等场景,后台能实时查看虚拟币消费明细,为运营策略调整提供数据支撑; 多维度认证:涵盖实名认证、工作认证、学历认证等环节,认证通过后给予专属标识展示,提升用户间的信任度,减少虚假交友风险,打造严肃的婚恋交友环境。 2. 内容管理:营造健康有序的互动环境 兴趣圈子运营:用户可创建同城交友、兴趣爱好等不同类型的圈子,发布动态、评论互动,平台可设置“付费进圈”规则,从中抽取佣金,拓展盈利渠道;后台支持圈子分类管理、关键词检索,方便用户找到契合的社交场景; 违规内容管控:将用户举报与帖子举报分开处理,管理员可快速查看举报内容,对违规账号、不良帖子进行封禁或删除操作,及时清理非法信息,保障平台内容合规。 3. 社交互动:提升用户粘性,提高匹配效率 多元化互动功能: 颜值交友:全屏展示用户形象,强化视觉吸引力,支持一键心动、关注等快捷操作; 灵魂匹配:基于算法分析用户兴趣、择偶标准,推荐契合度高的匹配对象,降低用户筛选成本; 漂流瓶玩法:用户可发布真心话、交友诉求等内容,增加随机社交的趣味性,消耗虚拟币可获得更多互动机会; 线下邀约:支持发起同城约会、小型联谊等线下活动,系统自动展示活动时间、地点、报名费用及倒计时,打通线上互动到线下见面的链路; 内容安全保障:强制要求用户上传真实头像,并对头像、相册内容进行违规检测,过滤低俗、非法图片,从源头保障平台社交环境健康。 4. 商业变现:线上线下联动,实现盈利闭环 媒婆推广返利:激活平台内的媒婆角色,媒婆推荐用户注册、促成匹配后可获得返利,借助社交裂变扩大用户规模,降低获客成本; 门店CRM管理:专为婚介公司设计,支持多门店统一管控、线上牵线匹配、会员资料分类存储、销售进度跟进、电子合同签署等功能,实现线下服务与线上系统的无缝衔接; 多元盈利模式:除虚拟币消费、付费进圈抽佣外,还支持会员等级体系(开通贵族享专属特权)、用户间礼物打赏抽佣、广告投放(首页轮播、圈子植入)等方式,形成多维度盈利矩阵。 三、核心特色:适配婚恋行业的差异化优势 1. 多场景适配,灵活性强 支持根据运营定位调整平台风格,无论是严肃婚恋、同城交友,还是高知人群、职场精英等垂直类社交场景,都能通过模板调整、功能取舍快速适配,无需重构核心代码。 2. 安全合规,运营无忧 内置头像、相册违规检测机制,配合多维度身份认证,从源头减少虚假信息与不良内容;后台细分管理员角色权限,不同岗位仅能操作对应模块,避免数据泄露或误操作。 3. 易拓展易部署,降低入局门槛 模块化的架构设计让二次开发更简单,如需新增视频聊天、心理测试等功能,可直接在现有框架上拓展;支持一键安装,普通虚拟主机或云服务器即可运行,无需复杂的环境配置,快速完成平台上线。 4. 易用性佳,降低运营成本 后台界面简洁直观,用户管理、内容审核、订单查看等核心操作流程清晰,非技术人员也能快速上手日常运营,无需配备专业的技术维护团队。 四、适用场景:精准匹配不同运营需求 1. 婚介公司/婚恋机构 可搭建线上平台承接线下业务,通过门店CRM系统统一管理客户数据,线上牵线与线下联谊结合提升服务效率,媒婆返利系统助力裂变获客,降低推广成本。 2. 创业团队/企业 快速入局婚恋行业,打造区域化婚恋平台或垂直类交友社区(如同城、职场、高知人群),开源特性支持灵活定制,试错成本低,可快速验证市场需求。 3. 个人开发者/站长 搭建轻量级婚恋交友平台,依托系统完善的功能实现自主运营,通过广告投放、虚拟币抽佣等方式实现盈利,一人即可完成日常运营管理。 获取源码 下载 下载地址:https://pan.quark.cn/s/cec8b4d4a985 提取码: 总结 该系统基于THINKPHP6+uni-app构建,实现微信小程序、H5、APP等多端适配,无需重复开发,降低维护成本; 功能覆盖用户真实认证、智能匹配、社交互动、商业变现全链路,适配婚介机构、创业团队等不同运营主体; 开源无捆绑限制,模块化架构易拓展,同时具备完善的安全机制,保障平台合规运营与盈利转化。
-
PyQt5程序打包发布:PyInstaller从入门到精通(exe单文件+避坑指南) 第18篇:PyQt5程序打包发布:从代码到exe可执行文件(全程避坑指南) 哈喽~ 欢迎来到PyQt5系列的第18篇!前面我们已经开发出了功能完整、界面美观、支持数据库持久化的多线程下载工具,但目前只能在Python环境中运行(需要安装PyQt5、requests等库)。想要把程序分发给普通用户(无需安装Python和任何依赖),就必须掌握 PyQt5程序打包发布 技术! mknfu5eq.png图片 今天我们就来学习最主流的打包工具 PyInstaller 的使用方法,手把手教你将下载工具打包成 Windows可执行文件(exe),同时解决打包过程中的各种坑(路径错误、资源丢失、体积过大、杀毒误报等),让你的程序可以直接分发给用户运行! 一、打包工具选择:为什么选PyInstaller? 在Python打包工具中,PyInstaller是最适合PyQt5程序的,原因如下: 跨平台支持:支持Windows(exe)、macOS(app)、Linux(可执行文件); 简单易用:一行命令即可完成打包,无需复杂配置; 深度兼容PyQt5:自动识别PyQt5的依赖库和资源文件,无需手动指定; 灵活定制:支持单文件/多文件打包、设置图标、隐藏控制台、添加版本信息等。 其他工具对比: cx_Freeze:兼容性较好,但配置繁琐,需编写setup.py脚本; py2exe:仅支持Windows,且对Python新版本兼容性差; nuitka:将Python代码编译为C语言,体积更小、运行更快,但学习成本高。 综上,PyInstaller是新手的最佳选择! 二、PyInstaller基础用法:从安装到打包 1. 安装PyInstaller 打开命令提示符(CMD)或终端,执行以下命令: pip install pyinstaller验证安装成功: pyinstaller --version出现版本号(如6.3.0)则表示安装成功。 2. 核心打包命令与参数 PyInstaller的核心命令格式: pyinstaller [参数] 你的脚本名.py常用参数说明(必记!) 参数作用示例-F/--onefile打包为单个exe文件(方便分发,启动稍慢)pyinstaller -F main.py-D/--onedir打包为多文件目录(启动快,包含多个依赖文件)pyinstaller -D main.py-w/--windowed隐藏控制台窗口(GUI程序必备,否则运行时会弹出黑窗口)pyinstaller -F -w main.py-i/--icon设置程序图标(支持.ico格式,不支持png/jpg)pyinstaller -F -w -i icon.ico main.py--add-data添加外部资源文件(如数据库、QSS、图片等)Windows:--add-data "db.db;." macOS/Linux:--add-data "db.db:."--name指定生成的exe文件名pyinstaller -F -w --name 下载工具 main.py-c/--console显示控制台窗口(用于调试,查看报错信息)pyinstaller -F -c main.py单文件 vs 多文件打包对比 打包方式优点缺点适用场景单文件(-F)只有一个exe,方便用户下载使用启动速度慢,运行时会解压到临时目录小型工具、需要快速分发多文件(-D)启动速度快,可直接修改资源文件生成一个目录,包含多个文件大型程序、需要频繁更新资源三、实战:打包多线程下载工具(带数据库+QSS) 我们以第17篇的 带数据库持久化的多线程下载工具 为例,演示完整打包流程。 步骤1:准备工作(打包前必做!) 整理项目文件:将所有相关文件放在同一个文件夹中,结构如下: 下载工具/ ├─ main.py (主程序脚本) ├─ download_history.db (数据库文件) ├─ icon.ico (程序图标,可选) └─ README.txt (使用说明,可选)注意:图标必须是 ico格式,如果只有png图片,可以用在线工具(如ConvertICO)转换。 测试脚本运行:确保在Python环境中能正常运行main.py,避免因代码错误导致打包失败。 步骤2:解决资源路径问题(最容易踩坑!) 打包后最常见的问题是 资源文件找不到(如数据库、QSS文件),原因是: 单文件打包时,程序运行会将exe解压到系统临时目录(C:\Users\用户名\AppData\Local\Temp\_MEIxxxxxx); 代码中使用的相对路径在打包后会失效,需要动态获取资源的真实路径。 解决方案:编写路径获取函数 在main.py中添加以下函数,用于获取打包后的资源路径: import sys import os def get_resource_path(relative_path): """ 获取打包后的资源文件路径 :param relative_path: 资源文件的相对路径 :return: 资源文件的绝对路径 """ if hasattr(sys, '_MEIPASS'): # 打包后,_MEIPASS指向临时解压目录 base_path = sys._MEIPASS else: # 开发环境,指向当前脚本目录 base_path = os.path.abspath(".") return os.path.join(base_path, relative_path)修改代码中的资源路径 将原来直接使用相对路径的地方,替换为get_resource_path函数: 数据库路径修改: # 原代码 self.db = DBManager("download_history.db") # 修改后 db_path = get_resource_path("download_history.db") self.db = DBManager(db_path) 如果有QSS文件(外部样式表): # 原代码 with open("style.qss", "r", encoding="utf-8") as f: qss = f.read() # 修改后 qss_path = get_resource_path("style.qss") with open(qss_path, "r", encoding="utf-8") as f: qss = f.read() 步骤3:执行打包命令 打开CMD,切换到项目文件夹目录(如cd D:\下载工具),执行以下命令: 方案1:打包为单文件(推荐分发) pyinstaller -F -w -i icon.ico --add-data "download_history.db;." --name 多线程下载工具 main.py -F:单文件打包; -w:隐藏控制台; -i icon.ico:设置图标; --add-data "download_history.db;.":将数据库文件添加到打包资源中(Windows用;分隔,macOS/Linux用:); --name 多线程下载工具:指定exe文件名为“多线程下载工具.exe”。 方案2:打包为多文件(推荐调试) pyinstaller -D -w -i icon.ico --add-data "download_history.db;." --name 多线程下载工具 main.py步骤4:查看打包结果 执行命令后,PyInstaller会在项目文件夹中生成3个目录/文件: build/:临时编译目录,可删除; dist/:最终打包结果,单文件打包会生成exe,多文件打包会生成一个目录; xxx.spec:打包配置文件(可修改后二次打包)。 打包成功后,dist文件夹中的多线程下载工具.exe(单文件)或多线程下载工具目录(多文件)就是可直接运行的程序! 四、打包常见问题与避坑指南(解决90%的问题) 打包过程中会遇到各种问题,以下是最常见的坑及解决方案: 问题1:打包后运行exe提示“找不到模块”(如No module named 'PyQt5') 原因:PyInstaller未识别到某些依赖模块; 解决方案: 确保已安装所有依赖库(pip install pyqt5 requests); 用--hidden-import参数手动指定缺失的模块,例如: pyinstaller -F -w --hidden-import PyQt5.QtWidgets --hidden-import requests main.py 问题2:运行exe时弹出黑窗口(即使加了-w参数) 原因:代码中使用了print()语句或有控制台输出; 解决方案: 注释掉代码中的所有print()语句; 确保-w参数正确添加,命令示例:pyinstaller -F -w main.py。 问题3:资源文件找不到(数据库、QSS、图片等) 原因:未使用get_resource_path函数,相对路径失效; 解决方案: 按照步骤2的方法,添加get_resource_path函数; 用--add-data参数正确添加资源文件; 单文件打包时,运行后可在任务管理器查看临时目录(_MEIxxxxxx),检查资源是否被解压。 问题4:打包后的exe体积过大(几百MB) 原因:PyInstaller会打包所有依赖库,包括Python解释器; 优化方案: 使用虚拟环境:创建干净的虚拟环境,只安装必要的库(PyQt5、requests),避免打包多余依赖; 删除无用模块:用--exclude-module参数排除不需要的模块,例如: pyinstaller -F -w --exclude-module tkinter --exclude-module test main.py 使用UPX压缩:下载UPX工具,用--upx-dir参数指定UPX路径,压缩exe体积(需自行下载UPX)。 问题5:杀毒软件误报病毒 原因:PyInstaller打包的exe会被部分杀毒软件误判为病毒(因为是未知程序); 解决方案: 将exe文件添加到杀毒软件的信任列表; 用--name参数设置合理的程序名,避免使用敏感词汇; 发布时提供程序的MD5校验值,证明文件未被篡改。 问题6:运行exe时提示“Failed to execute script main” 原因:代码有错误,或依赖库缺失; 解决方案: 去掉-w参数,用-c参数打包(显示控制台),运行exe查看具体报错信息; 根据报错信息修复代码(如缺少模块、路径错误等)。 四、进阶优化:定制打包配置(修改spec文件) PyInstaller打包时会生成一个 .spec文件(如main.spec),这是打包的配置文件,可直接修改它实现更灵活的打包。 什么时候需要修改spec文件? 需要添加多个资源文件; 需要设置程序的版本信息、公司名称等; 需要自定义打包逻辑(如压缩、加密)。 示例:修改spec文件添加资源 打开生成的main.spec文件,找到datas参数,添加需要打包的资源: # main.spec a = Analysis( ['main.py'], pathex=[], binaries=[], # 添加资源文件:格式为 (源文件路径, 目标路径) datas=[('download_history.db', '.'), ('style.qss', '.'), ('icon.ico', '.')], hiddenimports=['requests', 'PyQt5.QtWidgets'], hookspath=[], hooksconfig={}, runtime_hooks=[], excludes=[], noarchive=False, ) pyz = PYZ(a.pure, a.zipped_data, cipher=None) exe = EXE( pyz, a.scripts, a.binaries, a.zipfiles, a.datas, [], name='多线程下载工具', debug=False, bootloader_ignore_signals=False, strip=False, upx=True, upx_exclude=[], runtime_tmpdir=None, console=False, # 等同于 -w 参数,False=隐藏控制台 disable_windowed_traceback=False, argv_emulation=False, target_arch=None, codesign_identity=None, entitlements_file=None, icon='icon.ico' # 设置图标 )修改完成后,直接用spec文件打包: pyinstaller main.spec五、多平台打包说明 1. Windows打包注意事项 图标必须是 ico格式,分辨率建议为64x64或128x128; 打包时使用的Python版本最好与用户的一致(32位/64位); 避免使用系统盘根目录打包,防止权限不足。 2. macOS打包注意事项 需要在macOS系统上打包,无法在Windows上生成dmg文件; 打包命令:pyinstaller -F -w -i icon.icns main.py(图标为icns格式); 打包后需要签名才能在其他macOS设备上运行。 3. Linux打包注意事项 打包命令:pyinstaller -F -c main.py(Linux一般显示控制台); 生成的可执行文件需要设置执行权限:chmod +x main; 依赖系统的libc库,建议在低版本Linux(如Ubuntu 18.04)上打包,提高兼容性。 六、发布程序:给用户的最终版本 打包完成后,建议做以下工作,提升用户体验: 压缩文件:将exe文件或多文件目录压缩为zip包,方便用户下载; 编写使用说明:包含程序功能、运行方法、常见问题解决; 提供更新日志:记录版本更新内容; 测试兼容性:在不同版本的Windows(如Win7、Win10、Win11)上测试运行。 总结 打包核心流程:整理项目文件 → 解决路径问题 → 执行打包命令 → 测试exe → 优化发布; 必记参数:-F(单文件)、-w(隐藏控制台)、-i(图标)、--add-data(添加资源); 避坑关键:使用get_resource_path获取资源路径,用-c参数调试报错,虚拟环境减小体积; 进阶技巧:修改spec文件定制打包配置,添加版本信息,使用UPX压缩。 至此,我们的PyQt5系列教程就全部结束了!从基础控件到复杂实战,从界面美化到数据库交互,再到最终打包发布,你已经掌握了开发一个完整桌面应用的所有技能。现在,你可以动手开发自己的PyQt5程序了——比如记事本、音乐播放器、数据管理工具等!
-
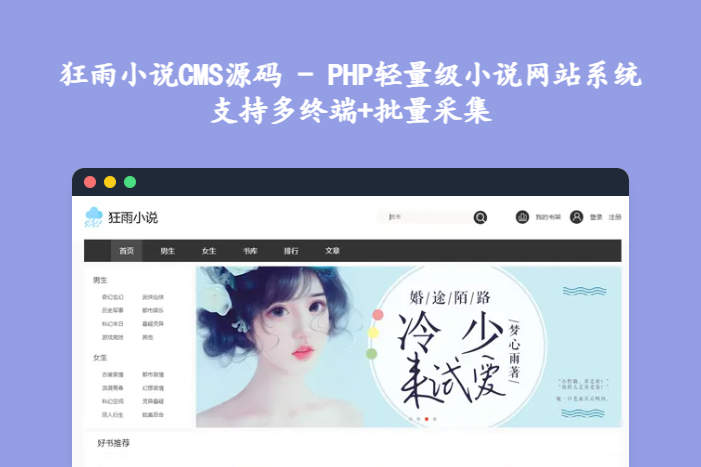
狂雨小说CMS源码 - PHP轻量级小说网站系统 支持多终端+批量采集 狂雨小说CMS源码:PHP轻量级小说网站解决方案(v1.5.5版) 狂雨小说CMS是一款专为小说网站打造的开源系统,基于PHP+MySQL技术栈构建,以灵活易用、功能全面为核心优势,无需复杂开发即可快速搭建涵盖多终端适配的小说平台。无论是个人站长快速上线小说站点,还是企业拓展文学内容业务,都能通过这套源码实现高效运营,已成为小说类网站搭建的热门选择。 mkmm4gwf.png图片 一、核心技术架构:轻量稳定,易部署好维护 1. 技术栈明细 模块技术选型优势说明后端核心PHP + ThinkPHP5.1 + MySQL技术成熟且轻量化,开发逻辑清晰,适配各类服务器环境,普通虚拟主机即可运行前端框架HTML5 + CSS3 + JavaScript响应式设计自动适配PC、手机、平板,无需单独开发多端版本,降低维护成本模板引擎内置标签模板系统支持模板一键切换与自定义修改,不懂代码也能调整网站外观,满足个性化需求部署支持Windows/IIS + Linux/Apache/Nginx兼容主流服务器系统与Web服务器,安装流程简单,新手可快速完成部署安全防护数据加密 + 目录权限控制经过严格测试,保障网站数据安全与运行稳定,避免恶意攻击导致的异常二、核心功能模块:覆盖小说网站全运营场景 1. 内容获取与管理:快速丰富站点资源 批量采集功能:支持采集各类小说网站数据,自动抓取小说章节、内容与封面,快速填充网站资源库; 数据联盟对接:不会设置采集规则也能获取海量小说数据,无需手动上传,降低内容运营门槛; 小说管理:后台可对小说进行分类、编辑、删除、上下架操作,支持按作者、类型、状态筛选管理,运营高效便捷; 章节管理:支持章节批量上传、排序调整、内容修改,自动生成章节目录,方便用户阅读导航。 2. 前端阅读体验:适配多终端,提升用户粘性 自适应阅读器:提供舒适的阅读界面,支持多种阅读模式切换,适配不同用户阅读习惯; 书架功能:用户可将喜欢的小说添加到个人书架,随时查看与继续阅读,提升使用便捷性; 最近阅读记录:自动保存用户阅读进度,再次访问时可直接续读,无需手动查找章节; 搜索联想功能:用户输入关键词时自动联想相关小说名称,快速定位目标内容,提高查找效率。 3. 用户互动与运营:增强站点活跃度 会员系统:支持用户注册、登录,提供个性化服务,可根据会员等级设置专属权益; 评论与打分:用户可对小说进行评论交流、评分,形成互动氛围,同时为其他用户提供参考; 排行榜功能:支持日榜、周榜、月榜、完结榜等多种榜单展示,突出热门小说,引导用户阅读; 分类导航:按男生、女生、题材等维度划分小说分类,如奇幻、都市、言情、历史等,方便用户精准找书。 4. 网站运营与拓展:灵活适配运营需求 广告管理:后台可智能添加、修改广告位,支持在首页、详情页、阅读页等位置投放广告,实现流量变现; 导航菜单自定义:支持自定义网站导航栏目,调整展示顺序与链接,适配不同运营策略; 首页轮播系统:可设置小说推荐轮播图,展示热门作品或新书,吸引用户点击; 友情链接管理:支持添加、编辑、删除友情链接,便于行业资源互换与SEO优化; API接口支持:提供丰富API接口,可对接第三方工具或进行二次开发,拓展功能边界; 插件市场:内置多款实用插件,支持按需安装,满足个性化功能需求。 三、核心特色:小说网站的差异化优势 简单易用:内置标签模板,无需专业代码知识,新手也能快速搭建并运营小说网站; 模板丰富:提供多种预设模板,支持自定义模板设计,可打造独具特色的网站外观; 高效变现:支持广告投放与会员体系,流量积累后可通过多种方式实现盈利; 性能优异:系统运行速度快,资源占用低,即使是普通配置的虚拟主机也能稳定承载高访问量; 适配性强:多终端自适应,用户在不同设备上都能获得流畅的阅读体验,扩大用户覆盖范围。 四、服务器环境要求 PHP版本:5.6及以上(低于5.6版本无法正常运行); 数据库:MySQL数据库; 目录权限:addons、application、config、extend、public、runtime、template、uploads等目录需设置777写入权限; 硬件配置:普通虚拟主机即可满足基础运行需求,流量较大时建议使用云服务器提升性能。 五、适用场景:谁适合选择狂雨小说CMS? 个人站长:想要低成本搭建小说网站,通过广告、会员实现盈利,无需复杂技术储备; 文学爱好者:希望打造专属小说分享平台,聚合优质小说资源,与同好交流互动; 中小企业/创业团队:计划进入网文行业,快速上线小说平台,测试市场需求与运营模式; 技术开发者:可基于源码二次开发,定制专属功能或界面,打造差异化小说站点。 下载 下载 下载地址:https://pan.quark.cn/s/8098ecf10c06 提取码:
-
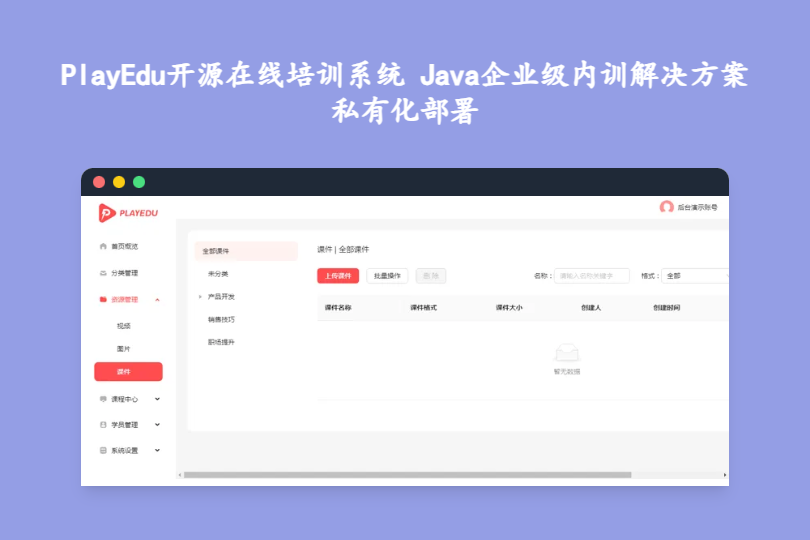
PlayEdu开源在线培训系统 Java企业级内训解决方案 私有化部署 PlayEdu是由白书科技团队联合培训行业专家打造的企业级开源在线培训系统,主打私有化部署与全流程培训管理,通过现代化技术架构与丰富功能模块,覆盖从“课程搭建-学员管理-学习追踪-考试评估”的企业培训闭环,同时支持多端适配与主流办公系统集成,现已成为中小企业搭建内部培训平台、教育机构拓展在线教学场景的优选方案,且提供开源版与企业版双版本,满足不同规模组织的定制化需求。 mkmkzldb.png图片 一、技术架构:前后端分离,现代化栈保障高性能 PlayEdu采用“高可用+易扩展”的架构设计,前后端彻底解耦,适配从中小型企业到大型集团的不同IT环境,技术选型覆盖当前主流稳定组件,具体架构细节如下: 1. 核心技术栈明细 模块技术选型优势说明后端核心SpringBoot 3 + Sa-Token基于Spring生态,性能优异且权限控制精细化,适配高并发培训场景前端框架React 18 / Vue3 + Element Plus双前端框架支持,均支持响应式设计数据存储MySQL 8.0 + Redis 7.0MySQL存储结构化数据,Redis缓存高频数据,降低数据库压力资源存储本地存储 / MinIO / 阿里云OSS灵活适配不同存储需求,均支持视频/文档/图片资源管理部署方案Docker + Jenkins + docker-compose容器化一键部署,支持自动化CI/CD流程,30分钟内可完成全系统搭建安全组件视频转码加密 + 防盗链 + Sa-Token从“资源安全-接口安全-用户安全”三重防护,避免培训内容泄露与非法访问二、核心功能模块:覆盖企业培训全流程 PlayEdu的功能设计围绕“企业实际培训需求”展开,既包含基础的课程与学员管理,也提供高阶的学习分析与考试防作弊能力,具体模块如下: 1. 组织与学员管理:适配企业架构,精细化运营 部门层级管理:支持无限级部门创建,可复刻企业实际组织架构,便于按部门批量指派课程、统计培训数据,避免跨部门资源混乱; 学员全生命周期管理: 账号管理:支持后台手动创建、Excel模板批量导入,自动生成初始密码并通过短信/邮件通知; 角色权限:区分多种角色,学员仅可查看指派课程,讲师可管理课程内容与批改作业,管理员拥有全系统配置权限; 学员画像:自动记录学员学习时长、课程完成率、考试分数等数据,生成个性化学习报告,辅助管理员识别培训薄弱人群。 2. 课程与资源管理:多形态内容,灵活编排 混合式课程搭建: 资源类型:支持视频、文档、图文等多种资源形态,支持断点续传与在线预览; 课程结构:支持章节式编排,可设置“必修/选修”章节,学员需完成前置章节才能解锁后续内容,保障学习连贯性; 资源管理:支持资源批量上传、分类归档、版本迭代,可设置资源访问权限,避免敏感培训材料外泄。 3. 学习过程追踪:实时监控,提升学习效果 学习进度自动记录:学员退出学习后自动保存进度,再次进入可续播课程,支持按章节查看完成状态,管理员可在后台实时查看全体学员进度; 学习行为分析:记录学员观看时长、互动次数、资源下载量等数据,生成部门/个人学习报表,直观呈现培训覆盖度与参与度; 学习提醒机制:通过系统消息、办公软件通知等方式,推送课程指派提醒、学习截止提醒、考试通知,降低学员遗漏率。 4. 在线考试与评估:闭环检验,量化培训成果 多元化题库管理:支持单选、多选、判断、简答等多种题型,可按课程/知识点分类创建题库,支持批量导入试题与自动判分(客观题); 灵活考试配置:可设置考试时长、及格分数、重考次数、防作弊规则,支持定时发布考试与随机抽题组卷,避免作弊与泄题; 成绩与分析:考试结束后自动生成成绩报告,支持查看错题解析与答题详情,管理员可按部门/岗位统计平均分、通过率,评估培训效果。 5. 系统集成与拓展:适配企业现有生态 办公系统集成:支持与主流办公系统对接,学员可通过现有办公账号一键登录,培训通知与学习提醒同步至办公软件,无需额外下载APP; 多端适配:支持PC端、移动端H5、微信小程序,学员可随时随地学习,适配通勤、出差等碎片化场景; 二次开发支持:开源版提供完整源码,接口文档完善,支持新增功能模块、定制化界面设计、对接第三方系统,满足企业个性化需求。 三、核心特色:企业级内训系统的差异化优势 1. 私有化部署,数据安全可控 所有培训数据、课程资源均存储在企业自有服务器或私有云,不经过第三方平台,避免核心培训内容与学员信息泄露,符合企业数据安全合规要求。 2. 多重安全防护,保障资源与学习质量 视频资源转码加密,搭配防盗链机制,防止培训视频被非法下载与传播; 学习过程防快进、防挂机,通过周期性互动验证(如随机弹窗答题),确保学员真实参与学习,避免“挂课刷时长”。 3. 易用性强,降低运营与学习门槛 管理员端:后台界面简洁直观,课程创建、学员管理、考试发布等操作流程清晰,非技术人员也能快速上手; 学员端:学习界面简洁无广告,课程查找与学习操作便捷,支持离线下载(企业版功能),适配不同网络环境。 4. 社区与技术支持完善 拥有活跃的开发者社区,用户可反馈问题、获取更新资讯,开源版提供基础文档与技术问答支持,企业版提供专属售后与定制化开发服务,保障系统长期稳定运行。 四、适用场景:谁适合选择PlayEdu? 1. 中小企业/大型集团 需求:搭建内部培训平台,统一管理新员工入职培训、在职技能提升、合规培训等场景; 优势:私有化部署保障数据安全,部门层级管理适配企业架构,批量操作功能降低运营成本。 2. 职业教育机构/企业大学 需求:拓展在线教学场景,实现“线上课程学习+线下实操结合”的混合式教学,或搭建纯线上培训平台; 优势:多形态课程支持、在线考试功能满足教学闭环,二次开发能力可定制化品牌界面与专属功能。 3. 政府机关/事业单位 需求:开展政策培训、技能培训,要求数据安全合规、学员管理精细化; 优势:私有化部署符合合规要求,多重安全防护与详细学习报表,满足培训考核与监管需求。 下载 playedu下载 下载地址:https://pan.quark.cn/s/df1e1838c01a 提取码: