找到
107
篇与
寒烟似雪
相关的结果
-
 RuoYi-Vue-OA开源办公系统_企业级协同OA流程办公框架 RuoYi-Vue-OA开源OA系统项目介绍 截图图片 一、源码概述 RuoYi-Vue-OA是一款依托Spring Boot框架开发的开源企业办公自动化协同管理系统。该项目实现前后端完整开源,代码资源全部公开透明,无功能阉割、无付费授权限制,遵循MIT开源协议,用户可完全免费商用、部署及二次开发。其前端配套项目为RuoYi-Vue-OA-UI,基于Vue.js技术栈搭建,界面设计简约现代化,交互体验流畅便捷,是搭建企业级协同办公平台的优质基础框架。 本系统具备极强的数据库兼容性,全面适配MySQL、Oracle、PostgreSQL、SQL Server、MariaDB、达梦DM等主流及国产数据库,拥有出色的跨环境移植能力与业务扩展能力。同时,系统内置权限管控、工作流引擎、消息推送、文件存储等全套核心功能组件,能够帮助企业快速搭建成型的内部数字化管理办公系统。 二、核心源码功能 (一)核心业务模块 个人事务管理:涵盖待办事项、已办事项两大核心功能,集中汇总用户各类审批及办公任务,清晰梳理个人工作进度,实现办公事务一体化管理。 流程管控功能:搭载成熟的Flowable工作流引擎,针对传统流程框架冗余数据表进行精简优化,支持可视化在线流程设计,可根据企业不同业务场景自定义审批流程,适配各类复杂办公审批需求。 资讯公告模块:支持企业统一发布官方公告、内部通知、行业新闻等内容,实现企业信息高效同步,保障全员信息互通。 日程管理功能:提供个人日程自定义编排、定时提醒等服务,帮助员工合理规划工作时间,规避工作遗漏,提升办公效率。 知识库模块:支持企业各类文档资料的上传、存储、分类共享与精准检索,搭建企业专属知识资源库,实现知识沉淀与复用。 企业通讯录:集成员工信息管理功能,可统一维护企业组织人员通讯录,支持快速查询、联系员工,便捷完成内部协作沟通。 业务编号自动生成:系统可自动生成审批单号、工单号、业务流水号等各类自定义业务编号,规范企业业务数据标准化管理。 运维管理功能:内置系统日志记录、运行状态监控、参数配置等运维工具,方便管理人员日常维护、故障排查与系统优化。 (二)系统配置模块 个人中心设置:支持用户自主修改头像、登录密码,自定义系统操作偏好,适配个人使用习惯。 系统基础配置:管理人员可统一配置系统全局参数,灵活分配菜单权限、角色权限,适配不同企业的组织管理架构。 (三)内置工具模块 系统管理:集成用户、角色、菜单、部门、岗位全方位管理功能,实现企业组织架构与人员权限的一体化管控。 系统监控:实时监测系统运行状态,支持日志溯源、在线用户统计与管理,保障系统稳定高效运行。 实用系统工具:内置数据库可视化管理、定时任务配置、代码自动生成器等工具,大幅降低开发及运维成本,提升项目落地效率。 三、项目核心特色 (一)主流先进技术架构 后端技术栈:采用Spring Boot快速搭建轻量化架构,依托Spring Security实现安全权限认证;搭配MyBatis轻量化ORM框架,简化数据操作;通过Redis、Redisson完成令牌认证与数据缓存,提升系统响应速度;基于MinIO搭建统一文件存储服务;借助RabbitMQ处理异步任务,缓解系统运行压力;通过Netty搭建Socket服务,实现消息实时推送;以Flowable作为核心流程引擎,支撑各类灵活的审批流程设计。 前端技术栈:基于Vue.js+Element UI搭建现代化交互界面,支持自适应响应式布局,可完美适配电脑端、移动端等多终端设备,适配多场景办公需求。 (二)精细化权限管控体系 系统采用Spring Security+Token+Redis的三重权限认证机制,安全稳定、保密性强。支持PC、移动端多终端同步认证登录,实现菜单动态加载、按钮级别的精细化权限控制,可针对不同角色、不同用户精准分配菜单、操作权限,满足企业分层分级的权限管理需求。 (三)流程表单高可配置化 支持用户自定义动态表单,内置多款通用表单组件,无需编码即可快速搭建业务表单;支持在线可视化流程设计,自由配置流程参数、审批节点;可动态调整权限菜单,自定义流程正文及附件规则;集成Office在线盖章功能,满足企业公文审批、电子签章等办公需求,适配各类复杂业务场景。 (四)全方位消息通知体系 基于Netty搭建独立Socket服务,实现待办任务、系统消息实时刷新推送,确保用户及时接收办公通知;同时兼容阿里云、腾讯云短信服务,可实现审批节点、业务通知等场景的短信提醒,多渠道保障信息触达。 (五)部署运维简单便捷 兼容市面上主流各类数据库,环境适配性极强,可适配不同企业的服务器部署环境;配套完整的项目启动与部署文档,上手门槛低;项目长期持续迭代更新,当前稳定版本为RuoYi-Vue 3.9.0,性能与安全性持续优化。 四、项目总结 RuoYi-Vue-OA是一款架构成熟、功能齐全、稳定性高的企业级开源协同办公系统。项目具备全栈开源、无任何付费套路、无功能隐藏的核心优势,覆盖企业日常办公全场景需求;依托精细化的权限管控体系与高度灵活的流程表单配置能力,可适配简单及复杂各类企业业务场景;整体采用行业主流企业级技术框架,稳定性与扩展性兼备。同时项目社区活跃度高,配套完善的技术文档与社群答疑支持,落地与二次开发保障充足。 无论是企业用于快速搭建内部数字化办公管理系统,还是开发人员用于技术学习、项目实战、二次开发,RuoYi-Vue-OA都是性价比极高、值得优先选择的开源项目。如果正在寻找一款部署便捷、功能完整、拓展性强的轻量化OA系统,该项目是绝佳选择。 RuoYi-Vue-OA下载 下载地址:https://pan.quark.cn/s/6b40cddf327d 提取码:
RuoYi-Vue-OA开源办公系统_企业级协同OA流程办公框架 RuoYi-Vue-OA开源OA系统项目介绍 截图图片 一、源码概述 RuoYi-Vue-OA是一款依托Spring Boot框架开发的开源企业办公自动化协同管理系统。该项目实现前后端完整开源,代码资源全部公开透明,无功能阉割、无付费授权限制,遵循MIT开源协议,用户可完全免费商用、部署及二次开发。其前端配套项目为RuoYi-Vue-OA-UI,基于Vue.js技术栈搭建,界面设计简约现代化,交互体验流畅便捷,是搭建企业级协同办公平台的优质基础框架。 本系统具备极强的数据库兼容性,全面适配MySQL、Oracle、PostgreSQL、SQL Server、MariaDB、达梦DM等主流及国产数据库,拥有出色的跨环境移植能力与业务扩展能力。同时,系统内置权限管控、工作流引擎、消息推送、文件存储等全套核心功能组件,能够帮助企业快速搭建成型的内部数字化管理办公系统。 二、核心源码功能 (一)核心业务模块 个人事务管理:涵盖待办事项、已办事项两大核心功能,集中汇总用户各类审批及办公任务,清晰梳理个人工作进度,实现办公事务一体化管理。 流程管控功能:搭载成熟的Flowable工作流引擎,针对传统流程框架冗余数据表进行精简优化,支持可视化在线流程设计,可根据企业不同业务场景自定义审批流程,适配各类复杂办公审批需求。 资讯公告模块:支持企业统一发布官方公告、内部通知、行业新闻等内容,实现企业信息高效同步,保障全员信息互通。 日程管理功能:提供个人日程自定义编排、定时提醒等服务,帮助员工合理规划工作时间,规避工作遗漏,提升办公效率。 知识库模块:支持企业各类文档资料的上传、存储、分类共享与精准检索,搭建企业专属知识资源库,实现知识沉淀与复用。 企业通讯录:集成员工信息管理功能,可统一维护企业组织人员通讯录,支持快速查询、联系员工,便捷完成内部协作沟通。 业务编号自动生成:系统可自动生成审批单号、工单号、业务流水号等各类自定义业务编号,规范企业业务数据标准化管理。 运维管理功能:内置系统日志记录、运行状态监控、参数配置等运维工具,方便管理人员日常维护、故障排查与系统优化。 (二)系统配置模块 个人中心设置:支持用户自主修改头像、登录密码,自定义系统操作偏好,适配个人使用习惯。 系统基础配置:管理人员可统一配置系统全局参数,灵活分配菜单权限、角色权限,适配不同企业的组织管理架构。 (三)内置工具模块 系统管理:集成用户、角色、菜单、部门、岗位全方位管理功能,实现企业组织架构与人员权限的一体化管控。 系统监控:实时监测系统运行状态,支持日志溯源、在线用户统计与管理,保障系统稳定高效运行。 实用系统工具:内置数据库可视化管理、定时任务配置、代码自动生成器等工具,大幅降低开发及运维成本,提升项目落地效率。 三、项目核心特色 (一)主流先进技术架构 后端技术栈:采用Spring Boot快速搭建轻量化架构,依托Spring Security实现安全权限认证;搭配MyBatis轻量化ORM框架,简化数据操作;通过Redis、Redisson完成令牌认证与数据缓存,提升系统响应速度;基于MinIO搭建统一文件存储服务;借助RabbitMQ处理异步任务,缓解系统运行压力;通过Netty搭建Socket服务,实现消息实时推送;以Flowable作为核心流程引擎,支撑各类灵活的审批流程设计。 前端技术栈:基于Vue.js+Element UI搭建现代化交互界面,支持自适应响应式布局,可完美适配电脑端、移动端等多终端设备,适配多场景办公需求。 (二)精细化权限管控体系 系统采用Spring Security+Token+Redis的三重权限认证机制,安全稳定、保密性强。支持PC、移动端多终端同步认证登录,实现菜单动态加载、按钮级别的精细化权限控制,可针对不同角色、不同用户精准分配菜单、操作权限,满足企业分层分级的权限管理需求。 (三)流程表单高可配置化 支持用户自定义动态表单,内置多款通用表单组件,无需编码即可快速搭建业务表单;支持在线可视化流程设计,自由配置流程参数、审批节点;可动态调整权限菜单,自定义流程正文及附件规则;集成Office在线盖章功能,满足企业公文审批、电子签章等办公需求,适配各类复杂业务场景。 (四)全方位消息通知体系 基于Netty搭建独立Socket服务,实现待办任务、系统消息实时刷新推送,确保用户及时接收办公通知;同时兼容阿里云、腾讯云短信服务,可实现审批节点、业务通知等场景的短信提醒,多渠道保障信息触达。 (五)部署运维简单便捷 兼容市面上主流各类数据库,环境适配性极强,可适配不同企业的服务器部署环境;配套完整的项目启动与部署文档,上手门槛低;项目长期持续迭代更新,当前稳定版本为RuoYi-Vue 3.9.0,性能与安全性持续优化。 四、项目总结 RuoYi-Vue-OA是一款架构成熟、功能齐全、稳定性高的企业级开源协同办公系统。项目具备全栈开源、无任何付费套路、无功能隐藏的核心优势,覆盖企业日常办公全场景需求;依托精细化的权限管控体系与高度灵活的流程表单配置能力,可适配简单及复杂各类企业业务场景;整体采用行业主流企业级技术框架,稳定性与扩展性兼备。同时项目社区活跃度高,配套完善的技术文档与社群答疑支持,落地与二次开发保障充足。 无论是企业用于快速搭建内部数字化办公管理系统,还是开发人员用于技术学习、项目实战、二次开发,RuoYi-Vue-OA都是性价比极高、值得优先选择的开源项目。如果正在寻找一款部署便捷、功能完整、拓展性强的轻量化OA系统,该项目是绝佳选择。 RuoYi-Vue-OA下载 下载地址:https://pan.quark.cn/s/6b40cddf327d 提取码:
-
Icefox v3.0.0 Typecho现代化博客主题 轻量响应式源码免费下载 Icefox v3.0.0 Typecho现代化博客主题 轻量响应式 完全开源 | 亲测可用 | 基于Bulma+Alpine.js构建 Icefox是一款专为Typecho博客平台开发的现代化轻量主题,当前版本为3.0.0,适配Typecho 1.2.0及以上版本,要求PHP 7.0.0及以上运行环境。主题采用Bulma CSS框架与Alpine.js轻量JavaScript框架联合开发,代码精简无冗余,在保证视觉美观的同时兼顾极致加载速度,界面简洁优雅且交互流畅,能够满足个人博客的各类展示与运营需求。 核心功能模块 界面设计 基于Bulma弹性网格系统实现全设备响应式布局,完美适配电脑、平板、手机等不同尺寸屏幕 内置日间/夜间双主题模式,支持一键切换,用户偏好自动保存至本地存储 集成Fancybox图片灯箱功能,支持图片放大查看、手势滑动切换 采用语义化HTML标签编写,代码结构清晰,搜索引擎友好度高 核心功能 完整的点赞互动系统,同时支持匿名用户和登录用户点赞,实时更新数据 多层级嵌套评论系统,搭配流畅交互动效,提升评论交流体验 文章列表无限滚动加载,无需手动翻页,下滑自动加载更多内容 支持音乐卡片短代码,可快速嵌入带封面、歌手信息的音乐播放器 长文章智能折叠功能,自动隐藏超出部分内容,点击即可展开全文 动态友情链接加载、自定义侧边栏、面包屑导航等基础博客功能 特色页面 专属游戏页面,可嵌入各类轻量小游戏,增加网站趣味性 时间轴式文章归档页面,按年份和月份清晰展示所有历史文章 可视化内容编辑页面,简化后台操作流程,提升内容发布效率 技术栈说明 后端依赖 核心框架:Typecho 1.2.0 及以上版本 运行环境:PHP 7.0.0 及以上版本 数据库支持:MySQL / MariaDB(需使用InnoDB引擎并支持外键约束) 必需PHP扩展:PDO、mbstring、json 前端技术 CSS框架:Bulma.min.css(纯CSS无JS依赖,模块化设计) JavaScript库: Alpine.js:轻量级响应式状态管理 Axios:处理HTTP异步请求 Fancybox:图片灯箱组件 ScrollLoad:实现文章列表无限滚动 字体方案:HarmonyOS Sans + DingTalk,跨平台兼容性好 安装步骤 下载主题文件 将主题文件下载后解压,上传至Typecho安装目录下的/usr/themes/文件夹中 安装配套插件 主题依赖同名icefox插件提供后端功能支持,将插件文件上传至/usr/plugins/文件夹 启用插件与主题 登录Typecho后台,先在「插件」页面启用icefox插件,再在「外观」页面启用Icefox主题 主题配置 进入主题设置页面,根据需求调整网站标题、导航菜单、侧边栏组件等参数 主题目录结构 icefox/ ├── assets/ # 静态资源目录 │ ├── css/ # 主题样式文件 │ ├── js/ # 前端交互脚本 │ ├── fonts/ # 字体文件 │ └── images/ # 内置图片资源 ├── components/ # 可复用组件目录 │ ├── modals/ # 模态框组件 │ ├── post/ # 文章相关组件 │ └── svgs/ # SVG矢量图标 ├── core/ # 核心工具函数库 ├── index.php # 首页模板 ├── header.php # 公共头部模板 ├── footer.php # 公共底部模板 ├── post.php # 文章详情页模板 ├── page.php # 独立页面模板 ├── archive.php # 分类/标签/归档页模板 ├── functions.php # 主题核心函数文件 └── comment_function.php # 评论系统函数文件使用说明 音乐卡片短代码 在文章编辑页面插入以下代码即可添加音乐播放器: [music title="歌曲名称" artist="歌手名字" cover="封面图片URL" src="音频文件URL"]自定义样式 简单修改:可在Typecho后台「外观-设置-自定义CSS」中添加样式代码 深度修改:直接编辑assets/css/icefox.css文件进行全局样式调整 主题切换 用户可通过页面右上角的图标切换日间/夜间模式,切换状态会自动保存至浏览器本地存储。 二次开发指南 样式修改:通过修改Bulma的Sass变量可实现全局样式统一调整,局部样式在对应CSS文件中修改 功能扩展:主题功能在functions.php中添加,前端交互在assets/js/icefox.js中编写,API接口在配套插件的Action.php中开发 数据库操作:推荐使用Typecho原生数据库API进行数据查询与处理 内置API接口 所有接口均通过/action/icefox?do={action}路径访问: 接口标识请求方法功能说明getLikesGET获取指定文章的点赞数据likePOST切换文章点赞状态addCommentPOST提交新评论getFriendLinksGET获取友情链接数据常见问题 点赞、评论功能无法使用:请确认已正确安装并启用icefox配套插件 无限滚动失效:清除浏览器缓存,检查assets/js/icefox.js文件是否完整加载 页面样式错乱:清除浏览器及CDN缓存,确认所有CSS文件已正确上传 适用场景 个人技术博客与知识分享平台 生活随笔与个人日记网站 文艺创作与作品展示博客 学生课程设计与毕业设计项目 主题截图 以下是Icefox博客主题的实际效果展示: 截图图片 下载地址 下载主题 下载地址:https://pan.quark.cn/s/f81b06edbd0f 提取码: 演示站 https://0ru.cn/ 温馨提示:本主题仅供学习和研究使用,请在使用过程中遵守相关法律法规。如需用于商业用途,请遵守GPL-3.0开源协议规定。
-
简约在线图书阅读网站HTML模板 静态读书站点源码免费下载 简约风在线图书阅读网站 HTML 静态模板 完全免费 | 亲测可用 | 适配多终端 对于想要搭建线上书屋、文学分享平台、电子书阅读站点的使用者而言,一套设计清爽、交互流畅的网站模板能够大幅降低建站成本。这款专为图书阅读场景打造的纯静态HTML模板,依托经典前端技术制作,不依赖数据库与后端程序,部署方式简单便捷,搭配简约耐看的视觉风格,十分适合文学爱好者、小型读书社群以及图书相关工作室搭建线上展示与阅读平台。 整体页面设计摒弃繁杂的装饰元素,以舒适的视觉体验为核心进行打造。配色柔和淡雅,长时间浏览文字内容也不易产生视觉疲劳,完美贴合阅读类网站的使用场景。页面布局主次分明,顶部导航栏规整清晰,能够引导访客快速区分不同书籍分类、新书推荐、热门读物、站点介绍等板块;主体区域采用分区展示形式,将书籍封面、名称、简介、阅读入口有序排列,信息呈现直观明了,访客可以快速筛选自己感兴趣的内容。 页面功能与布局细节 整套模板包含阅读类网站所需的全套基础页面,各页面之间跳转逻辑顺畅,形成完整的站点架构。首页作为门户核心,设置了轮播推荐位,可用来展示热门书籍、新书上架信息或是平台活动;下方划分出不同书籍分区,按照题材、风格、热度等维度对读物进行归类陈列,方便访客定向查找。 书籍列表页采用统一的卡片式布局,每一张卡片承载单本图书的核心信息,封面图搭配精简介绍,风格统一且整洁。点击对应书籍即可跳转至独立阅读详情页,阅读页面排版经过专门优化,文字行距、字体大小都经过调试,适配线上阅读习惯,同时页面保留基础的功能按钮,满足翻页、返回、收藏等常规操作需求。 除此之外,模板还配套了站点简介、关于我们、留言互动、联系渠道等辅助页面。留言板块可供书友交流心得、分享读后感,拉近社群成员之间的距离;介绍页面则可以用来讲述站点定位、建站初衷以及运营理念,帮助访客建立认知。 响应式适配与使用体验 模板全程采用响应式布局开发,深度适配电脑、平板、智能手机等各类主流设备。在电脑大屏环境下,页面以多列形式展示书籍内容,充分利用屏幕空间;切换至手机等小屏设备时,布局会自动转为单列样式,按钮、文字、图片同步自适应缩放,触控区域大小合理,有效避免移动端误触问题。无论访客使用哪种设备访问,都能获得连贯、舒适的浏览与阅读体验。 在浏览器兼容性方面,模板经过多轮测试,可稳定运行在Chrome、Firefox、Edge、Safari等主流浏览器中,不会出现页面错乱、功能失效等问题,覆盖绝大多数用户的使用环境。同时代码经过精简处理,去除冗余代码,页面加载速度表现良好,即便是网络环境一般的情况下,也能快速完成页面渲染。 模板定制与部署优势 作为纯静态模板,它最大的优势就是部署零门槛。使用者只需将全部源码文件上传至虚拟主机、云服务器或是各类静态托管平台,无需安装运行环境、无需配置数据库,上传完成后便可直接通过域名访问站点,几分钟就能完成上线操作。 代码结构划分清晰,模块独立性强,同时附带规范的代码注释,上手修改难度很低。即便只是具备基础前端知识,也可以自主替换站点Logo、修改站点名称、更换书籍图片与文字内容、调整导航分类。使用者可根据自身需求微调页面配色、字体样式,打造出具备个人特色的读书站点。如果有进阶开发能力,也能在此基础上拓展阅读权限、书架收藏、搜索查询等更多实用功能。 适用场景 个人线上读书博客、文学爱好者分享站点;小型书友社群、线下读书会配套线上平台;电子书展示、读物推荐类垂直网站;图书工作室、小型书商线上作品展示页;课程设计、前端练习演示项目。 模板截图 以下是该图书阅读网站模板的实际效果展示: 截图图片 下载地址 源码下载 下载地址:https://pan.quark.cn/s/343e05fd2ce9 提取码: 温馨提示:本模板仅供学习和研究使用,请在使用过程中遵守相关法律法规。如需用于商业用途,请保留作者版权信息。
-
悬赏猫 APP 推广单页源码免费下载 - 无需后台的自适应 HTML 下载页 悬赏猫APP下载推广单页HTML源码 纯静态全设备自适应版 mphrp7iq.png图片 源码概述 这是一套专门为悬赏猫APP量身打造的纯静态推广单页HTML源码,采用现代简约的设计风格,专为移动互联网时代的应用推广需求设计。整套源码仅包含前端静态代码,无需任何后端程序和数据库支持,上传即可运行,能够帮助用户在几分钟内快速搭建一个专业的APP下载推广页面。 页面采用响应式布局设计,能够完美适配从手机、平板到电脑的各种屏幕尺寸,确保不同设备的用户都能获得一致且优秀的浏览体验。无论是用于悬赏猫APP的官方下载引导,还是作为联盟推广的专属落地页,都能展现出专业的视觉效果和良好的转化能力。 核心功能特性 一键下载引导 页面内置醒目的APP下载按钮,支持直接跳转至应用商店或下载链接 提供二维码扫码下载功能,方便手机用户快速扫码安装 下载按钮采用高对比度设计,在各种设备上都清晰可见,有效提升转化率 多维度图文展示 预留了多个APP截图展示位,可直观展示应用的核心界面和功能 支持添加详细的功能介绍和优势说明,帮助用户快速了解产品价值 图文排版经过精心优化,信息层次清晰,阅读体验流畅 全内容可定制 所有文字内容、图片资源和链接地址均可自由修改 无需专业的编程知识,只需使用普通的文本编辑器和图片处理软件即可完成定制 支持更换配色方案和品牌标识,轻松打造符合自身品牌风格的推广页面 全设备响应式适配 采用先进的响应式布局技术,自动适配不同屏幕尺寸和分辨率 在手机端自动优化导航和按钮大小,确保触摸操作的便捷性 页面加载速度快,即使在移动网络环境下也能快速打开 零后端依赖 纯静态HTML源码,无需安装任何后端程序和数据库 无需复杂的服务器配置和环境搭建,上传即可使用 维护成本极低,无需担心后端安全漏洞和数据库故障 部署优势亮点 极速搭建,零门槛上手 整个部署过程仅需三步:下载源码、修改内容、上传服务器 即使是完全没有网站建设经验的新手,也能在10分钟内完成页面搭建 无需购买昂贵的服务器资源,普通的虚拟主机甚至免费静态空间即可运行 极致轻量,加载迅速 整套源码仅518.2KB,体积小巧,加载速度极快 经过优化的代码结构和图片资源,确保页面在各种网络环境下都能快速打开 良好的加载体验能够有效降低用户跳出率,提升推广效果 悬赏猫APP推广单页 下载地址:https://pan.quark.cn/s/079ba57ad454 提取码: 设计美观,转化高效 采用现代简约的设计风格,色彩搭配和谐,视觉效果出色 页面布局符合用户浏览习惯,重点信息突出,引导路径清晰 经过实际推广验证的页面结构,能够有效提升APP下载转化率 灵活通用,适用性广 不仅适用于悬赏猫APP,只需简单修改内容和图片,即可用于其他任何APP的推广 可作为临时活动页、产品介绍页、品牌宣传页等多种用途使用 完全开源免费,用户可以根据自己的需求进行任意修改和二次开发 服务器环境要求 由于该源码为纯静态HTML页面,对服务器环境没有任何特殊要求,几乎所有的服务器环境都能完美支持: 支持Apache、Nginx、IIS等所有主流Web服务器 支持任何支持静态文件访问的虚拟主机、云服务器或静态托管服务 无需安装任何PHP、Node.js等后端运行环境 无需配置数据库和任何扩展 总结 这款悬赏猫APP下载推广单页HTML源码是一款实用性极强的推广工具,它以极低的部署门槛、优秀的设计效果和良好的用户体验,成为APP推广人员的得力助手。 与需要复杂后端支持的推广系统相比,这款纯静态单页源码最大的优势在于其简单易用和高效稳定。它不需要任何专业的技术知识,任何人都能快速搭建起一个专业的APP推广页面,同时还能保证页面的加载速度和稳定性。 无论是个人推广者还是小型团队,只要需要快速搭建一个APP下载推广页面,这款源码都是一个非常理想的选择。它不仅能够帮助你节省大量的时间和开发成本,还能为你带来出色的推广转化效果。
-
ImgURL 免费下载 - 支持图片鉴黄的 PHP 轻量级开源图床源码 ImgURL:基于PHP+SQLite的轻量级开源免费图床程序完整源码 mphrhq8y.png图片 注:如果您不熟悉服务器环境配置或源码安装步骤,可联系客服购买增值服务,快速完成图床系统搭建。系统概述 ImgURL是一款专为个人用户和小型团队设计的轻量级开源图床程序,采用PHP+SQLite 3技术栈开发,彻底摆脱了对MySQL等独立数据库的依赖,部署过程极其简单,只需将源码上传至服务器即可运行。 该程序聚焦于提供高效便捷的图片托管与管理体验,集成了从上传、处理到安全防护的全流程功能,同时保持了极致的轻量特性。无论是个人博主用于托管博客图片,还是独立开发者用于项目素材管理,ImgURL都能提供稳定可靠的支持。作为完全开源的项目,用户可以自由修改源码,进行二次开发以满足个性化需求。 核心功能模块 全场景便捷上传体验 支持拖拽上传、多图批量上传、Ctrl+V剪贴板粘贴上传和URL远程上传四种主流上传方式 上传过程实时反馈进度,已完成的图片可立即预览和获取外链 无需复杂操作,即使是新手用户也能快速上手 智能图片处理能力 内置灵活的图片裁剪工具,支持自定义尺寸和比例裁剪 上传后自动生成不同规格的缩略图,大幅提升图片浏览和加载速度 提供单张和批量图片压缩功能,有效减少存储空间占用和带宽消耗 支持多种常见图片格式的处理和转换 全方位安全防护机制 可灵活设置访客每日上传数量限制,有效防止平台被恶意滥用 集成智能图片鉴黄算法,自动检测并标记可能含有不良内容的图片 支持批量鉴黄操作,快速审核历史上传的所有图片,保障平台内容安全合规 内置文件类型验证,防止恶意文件上传 灵活的系统集成能力 提供标准的API接口,支持通过程序实现图片的上传、删除和管理操作 接口文档简洁明了,方便与个人博客、论坛、CMS系统、小程序等第三方应用无缝对接 支持API密钥管理,保障接口调用的安全性 系统优势亮点 极致轻量,部署零门槛 采用SQLite嵌入式数据库,无需单独安装和配置数据库服务 整个程序仅3.81MB,体积小巧,上传到任意支持PHP的虚拟主机即可运行 安装过程简单,几分钟内即可完成图床系统的搭建 操作简单,界面友好 采用现代化简洁界面设计,操作逻辑清晰直观 无需专业的技术知识,普通用户也能轻松掌握所有功能 响应式设计,支持在电脑、平板和手机等多种设备上正常使用 批量处理,高效管理 支持批量上传、批量压缩和批量鉴黄,大幅提升图片管理效率 提供图片列表管理功能,方便用户查看、搜索和管理已上传的图片 支持一键复制多种格式的图片外链,快速分享到各个平台 功能全面,实用性强 涵盖了图床系统所需的所有核心功能,同时保持了程序的轻量性 持续的版本更新和功能优化,不断提升系统的稳定性和用户体验 完全开源免费,无任何功能限制,用户可以自由使用和修改 服务器环境要求 环境组件最低版本要求备注说明PHP5.6及以上推荐使用PHP 7.4及以上版本以获得更好的性能和安全性PDO_SQLite-必须开启,用于SQLite数据库的连接和操作GD2-必须开启,用于基础图片处理和缩略图生成ImageMagick-可选,用于更高级的图片压缩和格式转换功能fileinfo-必须开启,用于验证上传文件的类型和MIME信息pathinfo-PHP系统内置函数,用于文件路径的解析和管理总结 ImgURL是一款性价比极高的轻量级开源图床解决方案,它以极低的部署门槛、全面的功能特性和优秀的用户体验,成为个人和小型团队搭建专属图床的首选。 与其他需要复杂数据库配置的图床系统相比,ImgURL的最大优势在于其极致的轻量性和易用性,即使是没有任何服务器管理经验的用户,也能快速搭建起属于自己的图床平台。同时,其完善的图片处理功能、安全防护机制和API接口支持,也能满足大多数用户的日常使用需求。 ImgURL 下载地址:https://pan.quark.cn/s/cc19c0e7f3a7 提取码: 如果您正在寻找一款简单易用、功能全面且完全免费的图床程序,ImgURL绝对是一个值得尝试的选择。
-
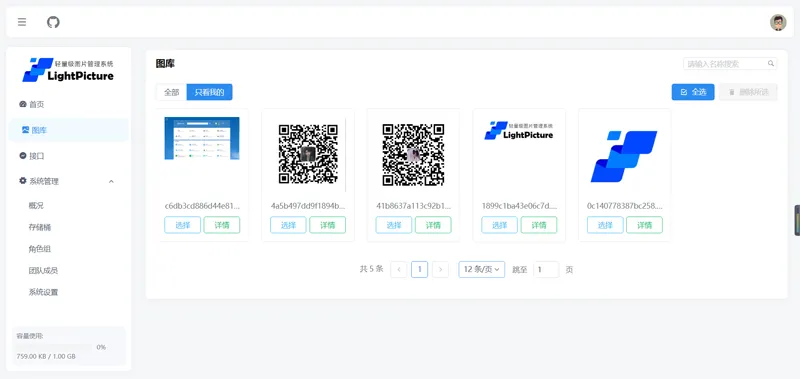
LightPicture v1.2.2 开源图床系统 - ThinkPHP+Vue 前后端分离图床源码 LightPicture v1.2.2:基于ThinkPHP+Vue的前后端分离开源图床系统完整源码 mphr8x3c.png图片 注:如果您不熟悉服务器环境搭建或源码安装流程,可以联系官方客服购买专业的增值服务,获得一对一技术支持。系统概述 LightPicture是一款专为现代互联网环境打造的高性能图床解决方案,采用业界主流的PHP后端+Vue前端技术栈,严格遵循前后端分离架构设计,为个人和团队提供了一个高效、安全、易用的图片托管与分享平台。该系统不仅支持本地服务器存储,还完美兼容阿里云OSS、腾讯云COS、七牛云等多家主流第三方云存储服务,用户可以根据自身需求灵活选择存储方案。 作为一款完全开源的项目,LightPicture提供了完整的源代码和清晰的代码结构,开发者可以基于此进行深度的二次开发和功能定制,快速打造符合自己业务需求的专属图床系统。 核心功能特性 多样化上传体验 支持批量多图同时上传,大幅提升工作效率 提供拖拽上传、剪贴板粘贴上传等多种便捷上传方式 上传过程中实时显示进度和预览效果,随时掌握上传状态 内置全屏图片预览功能,支持一键复制多种格式的图片外链,方便快速分享到各个平台 完善的用户与权限管理 支持多用户注册和独立账号体系,每个用户拥有专属的存储空间 提供灵活的用户分组管理功能,管理员可将用户分配到不同组别 支持为不同用户组分配独立的存储桶和精细化的操作权限 用户只能在自己的权限范围内进行图片的上传、删除和查看操作,保障数据安全 强大的系统管理能力 完整的操作日志记录功能,详细记录所有用户的每一次操作 提供直观的可视化日志界面,方便管理员进行事件溯源和安全审计 支持全局配置用户初始存储空间大小,合理分配系统资源 管理员可以单独为特定用户调整存储空间配额,满足不同用户的差异化需求 丰富的API接口 提供标准的RESTful API接口,支持通过接口进行图片的上传和删除操作 接口文档清晰完整,方便与个人博客、论坛、CMS等其他系统进行无缝集成 支持API密钥管理,保障接口调用的安全性 系统优势亮点 卓越的性能与稳定性 前后端分离的架构设计,有效提升了系统的响应速度和用户体验 经过深度优化的代码结构和数据库索引设计,确保系统在高并发场景下仍能稳定运行 完善的错误处理机制和异常捕获,最大限度减少系统宕机风险 灵活的存储方案 同时支持本地存储和多家主流第三方云存储服务 用户可以随时切换存储方式,无需担心数据迁移问题 支持存储桶的独立管理,方便对不同类型的图片进行分类存储 现代化的界面设计 采用原创的Geek扁平化设计风格,界面简洁大气,操作逻辑清晰 前端基于Vue框架开发,提供流畅的交互体验和快速的页面加载速度 支持多语言切换和自定义主题,满足不同用户的个性化需求 高度的可扩展性 模块化的代码架构,便于功能的扩展和维护 提供丰富的钩子函数和插件机制,开发者可以轻松添加新功能 持续的版本更新和社区支持,不断完善系统功能和修复已知问题 服务器环境要求 环境组件最低版本要求备注说明PHP7.2及以上必须开启PDO、fileinfo、curl扩展MySQL5.5及以上推荐使用MySQL 5.7或8.0版本Web服务器Apache/Nginx需要配置Rewrite规则其他-需要支持ZipArchive库总结 LightPicture是一款功能全面、性能优异的开源图床系统,它不仅提供了用户日常使用所需的所有基础功能,还具备完善的管理后台和强大的扩展能力。无论是个人博主用于托管博客图片,还是小型团队用于内部图片共享,甚至是企业用于搭建专属的图片管理平台,LightPicture都能很好地满足需求。 LightPicture-1.2.2.zip 下载地址:https://pan.quark.cn/s/dbcaa01c3ad6 提取码: 其开源免费的特性、灵活的存储方案以及现代化的界面设计,使其在众多图床系统中脱颖而出。如果您正在寻找一款可靠的图床解决方案,LightPicture绝对是一个值得考虑的选择。
-
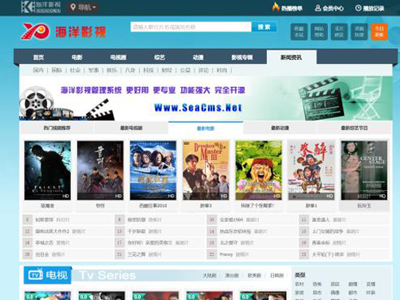
海洋CMS(SeaCMS) v13.1 开源免费高清影视点播系统_PHP+MySQL影视网站源码下载 海洋CMS(SeaCMS) v13.1:开源免费高清影视点播系统,5分钟搭建专业视频网站 mpc60npo.png图片 如果你正在找一套开源免费的PHP影视点播系统,想快速搭建电影、电视剧、综艺等视频网站,那么海洋CMS(SeaCMS)这个方案值得重点考虑。它采用PHP+MySQL架构,原生PHP代码保证了访问速度和负载能力,同时内置大量SEO友好功能,帮助站长在搜索引擎中获得更好的收录和排名。【turn1fetch0】【turn2search2】 下面从功能特点、安装配置、SEO优势等方面,详细拆解这套开源影视系统的核心价值。 一、海洋CMS(SeaCMS) 是什么?适合做什么站? 海洋CMS(SeaCMS)是一套专门为视频站点设计的高清影视点播系统,适用于: 电影网站 电视剧在线点播平台 综艺、动漫、短视频等内容站 它最大的优势是:灵活、方便、人性化,可以让站长在极短时间内搭建起一个拥有海量视频信息的行业网站,官方甚至给出“5分钟建站”的承诺。 简单理解: 你只需要准备好域名、服务器和视频资源,剩下的网站结构、播放页、列表页、搜索、专题等,都可以用海洋CMS快速实现。 二、核心功能与特点:为什么选择海洋CMS? 1. 快速架设专业视频网站 极低的上手门槛:按照官方教程,5分钟即可完成基础安装,大幅缩短建站周期。 原生PHP+MySQL架构,不依赖臃肿框架,访问速度和负载能力更有保障,适合视频这种高并发场景。 2. 一键转换Max模板和数据,迁移更轻松 支持一键转换原Max程序的模板和数据,实现网站从旧平台到海洋CMS的无缝迁移。 对于已经在用其他影视系统的站长来说,可以极大减少改版、升级带来的成本和数据风险。 3. 人性化功能设计,专注内容运营 内置“超前定时执行任务”等机制,可以自动处理采集、更新、缓存清理等工作。 站长可以把更多精力放在内容运营和用户体验上,而不是重复性操作上。【turn1fetch0】【turn2search2】 4. SEO 友好:百度结构化数据 + 搜索引擎地图 专门为SEO优化开发了一系列功能,如: 百度结构化数据生成(视频、文章等内容更易被识别为富摘要) 搜索引擎地图(Sitemap)自动生成,方便蜘蛛抓取全站链接 这些设计对提升网站在百度等搜索引擎中的收录和排名非常有帮助,特别适合流量站、权重站。 5. 专题管理:多种分类组合,内容更“立体” 全新设计的专题管理功能,支持: 按分类 按扩展分类 按剧情分类 三种模式组合,让网站内容组织更有层次,也更有利于长尾关键词覆盖。 6. 模板标签丰富,模板制作更简单 提供简单易用且丰富的模板标签,方便开发者或美工快速制作个性化模板。 即使你不是特别精通PHP,也能通过标签调用实现复杂的数据展示,让网站看起来更专业。 7. 完全开源、无加密,安全与扩展兼得 基于PHP+MySQL技术开发,完全开源、没有任何加密代码。 对于有开发能力的站长,可以自由二次开发、增加功能、对接第三方支付/登录等; 同时官方长期维护,持续修复安全问题,整体比较健壮。 8. 易用性:模板多、插件全、升级平滑 官方和社区提供大量模板与插件,可以快速搭建不同风格的影视站。 架构稳健,支持平滑升级,避免大版本升级时出现“全站崩掉”的情况。 三、安装与配置:宝塔面板为例的保姆级教程 1. 环境要求 支持多种服务器环境,常见的组合包括: Windows:IIS/Apache/Nginx + PHP(5.x/7.x) + MySQL(5.x) Linux/Unix:Apache/Nginx + PHP(5.x/7.x) + MySQL(5.x) 推荐使用 PHP 7.x + MySQL 5.6/5.7,以获得更好的性能与兼容性。 2. 安装步骤(以宝塔面板为例) 下载海洋CMS v13.1源码包,将upload目录里的所有文件上传到网站根目录(如 /www/wwwroot/你的域名)。 海洋cms下载 下载地址:https://pan.quark.cn/s/2f1612c80eaf 提取码: 在浏览器中访问 http://你的域名/install/index.php,进入安装向导,阅读并同意安装协议。 系统会自动进行环境检测,通过后按提示填写: 数据库配置(主机、库名、用户名、密码) 网站基本配置(站点名称、管理员账号密码等) 安装完成后,为了安全,务必删除 install 目录,防止被他人重复安装。 登录后台,根据需要配置伪静态规则、缓存、水印、采集规则等。【turn1fetch0】【turn2search6】 注意: 海洋CMS目前对子目录支持不够完美,建议直接安装在根目录,不要放在二级目录中运行,否则可能出现路径错误等问题。四、SEO 优化实战:如何用海洋CMS做出一个高收录影视站? 光有“SEO友好”的系统还不够,实际运营中你还需要做好几件事,才能真正把SEO价值榨干: 1. 关键词布局:从首页到播放页全链路覆盖 首页:主做“电影网站”“在线影视”“免费电影”等高指数词; 分类页:做“最新电影”“热播电视剧”“综艺大全”等分类词; 播放页:围绕“片名+在线观看”“片名+百度云”“片名+高清完整版”等长尾词布局; 利用专题页,集中做某类主题词,如“2024年高分电影”“国产剧推荐”等。 海洋CMS的分类+专题组合,正好可以帮你把关键词结构梳理清晰。 2. 内链结构:用标签和推荐串联全站 合理使用模板标签,实现: 相关视频推荐 同主演/同导演作品 同分类热门内容 一方面提升PV和停留时间,另一方面让搜索引擎更容易抓取深层页面,提升收录率。 3. 速度与体验:原生PHP + 合理缓存 原生PHP+MySQL架构,本身就比很多臃肿的CMS更快,但视频站还需要: 开启页面缓存、数据缓存 使用CDN加速静态资源 优化图片和视频封面加载 页面加载速度已经是百度排名因素之一,这一点对影视站尤其重要。 4. 结构化数据与Sitemap:让百度更“看得懂”你的站 开启海洋CMS内置的百度结构化数据,让视频内容更容易以富摘要形式展现; 定期生成并提交XML Sitemap,帮助搜索引擎更快发现新内容,减少死链、孤岛页。 五、总结:海洋CMS适合哪些人?怎么选? 综合来看,海洋CMS(SeaCMS) v13.1非常适合以下几类站长: 想快速搭建一个电影/电视剧/综艺类视频网站的个人站长; 手里已有其他影视系统,想平滑迁移并升级SEO能力的站长; 有一定PHP基础,希望二次开发,做更复杂运营逻辑的开发者。 它开源、免费、功能齐全、SEO友好,再配合你自己的内容与运营,完全有机会做出一个高收录、高权重的影视站点。
-
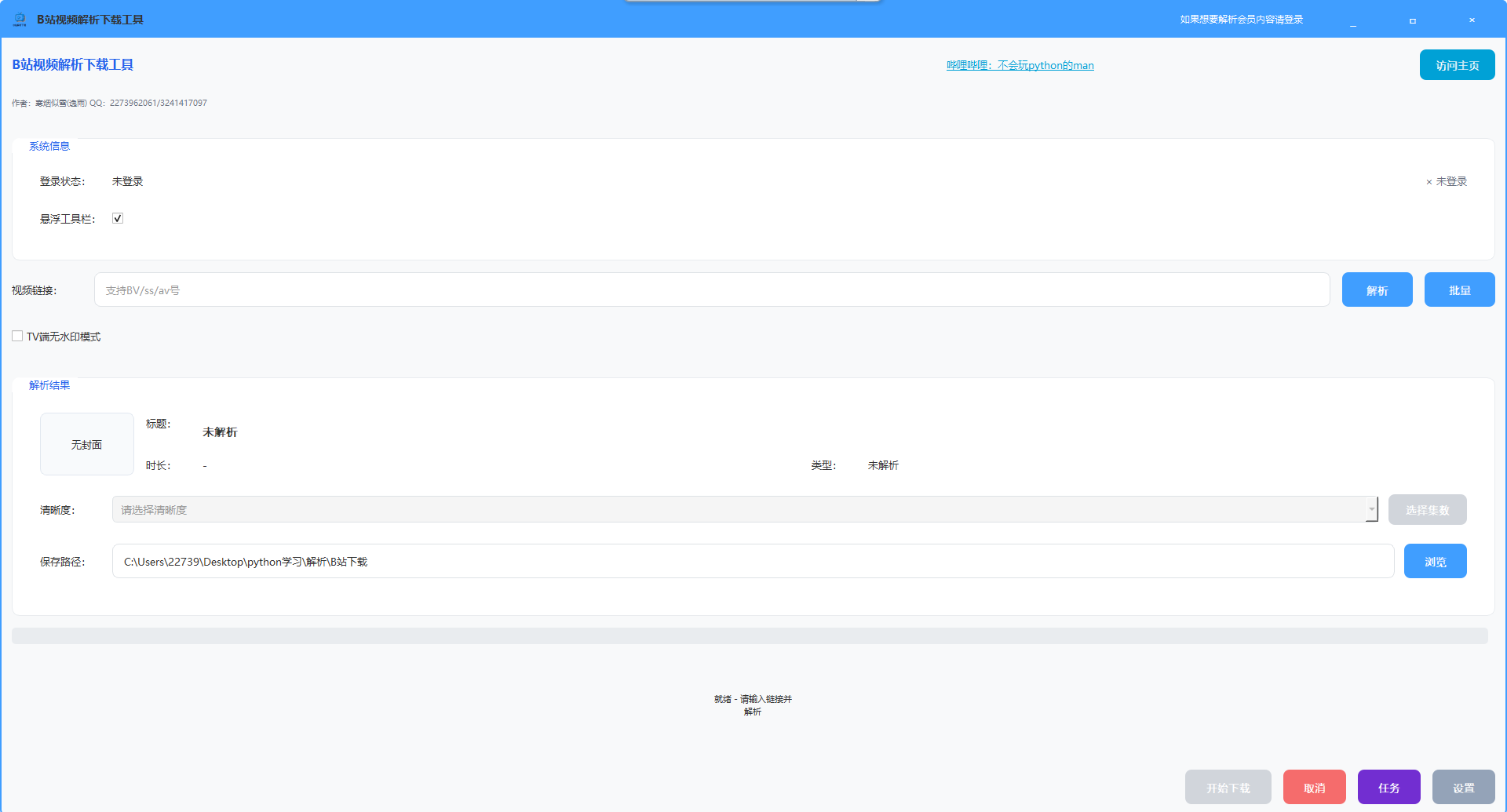
GitHub开源:bilibilidownloadtool,B站视频下载神器(附完整使用教程) 前言 mmu1pwgd.png图片 你是否想把B站优质教程、番剧、课堂视频保存到本地离线观看?是否苦于官方缓存无法导出、批量下载麻烦、会员视频无法保存?今天给大家带来我独立开发的GitHub开源项目——bilibilidownloadtool,一款纯Python编写、带图形界面的B站视频解析下载工具,支持BV/av/ss全链接解析、4K超清、HEVC高效编码、批量下载、后台运行、断点续传,会员视频通过Cookie即可轻松下载,完全免费开源,个人学习必备! 项目地址:https://github.com/NANblogink/bilibilidownloadtool 一、工具亮点(SEO密集区) bilibilidownloadtool是专为B站生态打造的全能视频下载工具,相比同类工具优势明显: 全链接兼容:支持BV号、av号、ss号、番剧/合集/课堂/充电视频链接一键解析 超清画质自由:从标清到4K全覆盖,支持HEVC编码,画质更好体积更小 会员内容支持:Cookie登录即可下载大会员专属视频,支持多方式登录与人机验证 批量+后台下载:多集同时下载,关闭窗口后台继续,任务独立控制暂停/继续 稳定可靠:断点续传、自动清理临时文件、下载完成自动合并音视频,无无声问题 易用GUI:PyQt5编写界面,悬浮球快捷操作,新手开箱即用 二、适用人群(精准匹配搜索意图) 学生党:下载网课、考研、编程教程离线反复学习 动漫爱好者:批量保存番剧,避免下架丢失 内容创作者:素材收集、高清视频存档 技术学习者:研究Python GUI、网络请求、API解析、音视频处理 三、快速上手(步骤清晰,利于收录) 1. 环境准备 Python 3.7及以上版本 安装依赖: pip install PyQt5 requests plaintext 2. 启动程序 克隆/下载项目后,执行: python main.py plaintext 3. 下载流程(SEO友好短句) 粘贴B站视频链接 → 2. 点击解析链接 → 3. 选择集数与清晰度 → 4. 设置保存路径 → 5. 开始下载 4. 会员视频下载 浏览器登录B站 → 开发者工具复制Cookie → 填入工具验证保存 → 即可解析下载会员内容 四、核心功能详解(提升页面权重) 1. 智能解析引擎 基于B站官方API,正则提取BV/av/ss,自动识别视频类型,返回真实播放地址与清晰度列表。 2. 多线程下载管理 采用ThreadPoolExecutor线程池,支持并发下载、断点续传、实时进度显示,网络异常自动重试。 3. 音视频自动合并 内置FFmpeg,下载后自动合成MP4,彻底解决“有画面无声音”问题。 4. 任务管理系统 支持暂停/继续/删除,后台运行不中断,重启自动恢复未完成任务,文件列表支持搜索筛选。 5. 安全合规说明 本工具仅限个人学习研究,严禁商用,请遵守B站用户协议与版权法规,责任自负。 五、常见问题(解决用户痛点,提高停留) Q:解析失败怎么办? A:检查链接有效性,会员视频确保Cookie有效且权限正常。 Q:下载后没有声音? A:正常现象,工具会自动合并音视频,完成后即可正常播放。 Q:支持哪些视频类型? A:普通视频、番剧、合集、课堂、充电专属视频全覆盖。 Q:HEVC有什么用? A:相同画质下文件更小,节省存储空间,高清视频更流畅。 六、技术实现(吸引技术用户,增加权威) 语言:Python 3.7+ GUI:PyQt5 网络:requests 音视频:FFmpeg 架构:模块化设计,解析器、下载器、任务管理器、UI分离,易于维护扩展 七、项目地址与更新 GitHub:https://github.com/NANblogink/bilibilidownloadtool 持续更新,欢迎Star、Fork、提交Issue与PR!
-
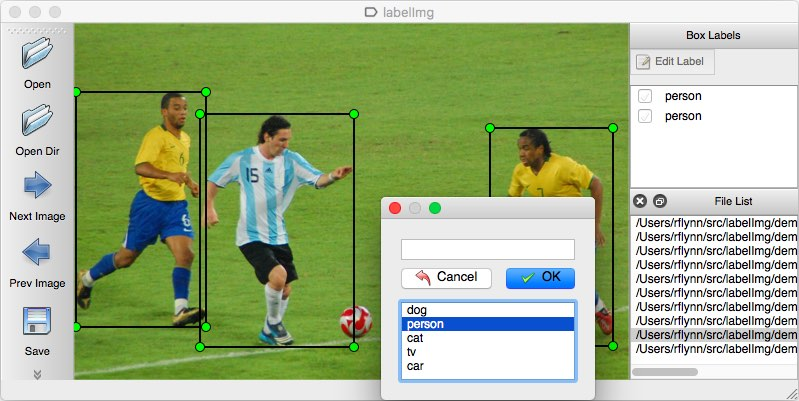
LabelImg开源图像标注工具 目标检测数据集标注利器 LabelImg开源图像标注工具 目标检测数据集标注利器 LabelImg是一款基于Python和Qt开发的开源图像标注工具,专为目标检测、图像分类等机器学习/深度学习场景的数据集制作设计,支持PASCAL VOC、YOLO、CreateML等主流标注格式,界面简洁、操作高效,是个人研究者与团队制作标注数据集的必备工具。 mmamal57.png图片 核心功能模块 1. 多格式标注兼容 PASCAL VOC格式:生成XML标注文件,适配经典目标检测数据集标准,包含目标类别、边界框坐标等完整信息 YOLO格式:生成TXT标注文件,按YOLO系列算法要求存储归一化后的边界框坐标与类别索引,直接适配模型训练 CreateML格式:生成JSON标注文件,适配Apple CreateML训练框架,满足iOS生态模型开发需求 2. 可视化高效标注 矩形框(BBox)标注:支持鼠标拖拽绘制、调整边界框,精准框选目标对象 标签预设与快速选择:支持提前创建/导入标签列表,标注时一键选择标签,避免重复输入 图像操作辅助:支持图像放大/缩小、平移,方便标注小目标或细节区域;支持一键切换上一张/下一张图像,提升标注流畅度 3. 标注效率工具 基础编辑功能:完整支持撤销(Undo)、重做(Redo)、复制/粘贴标注框,适配误操作修正与相似目标快速标注 自动保存与验证:支持标注文件自动保存,防止数据丢失;内置标签验证功能,避免空标签、格式错误等问题 标注进度管理:支持查看已标注/未标注图像列表,清晰掌握标注进度 工具核心特色 1. 开源免费,生态成熟 项目在GitHub开源,拥有活跃的社区支持,文档完善,允许自由使用、修改与定制,无商用限制。 2. 跨平台全适配 原生支持Windows、macOS、Linux三大操作系统,提供pip一键安装、源码运行等多种使用方式,适配不同技术环境。 3. 轻量高效,资源占用低 基于Python+Qt构建,界面简洁无冗余功能,运行时资源占用少,标注流程顺畅,适合大规模数据集连续标注。 4. 高度可定制化 支持自定义标签列表、修改快捷键,适配不同团队的标注规范与个人操作习惯;源码结构清晰,可基于需求二次开发扩展功能(如多边形标注、AI辅助预标注等)。 使用指南 1. 安装方式 pip一键安装(推荐): pip install labelimg 源码运行: 克隆GitHub仓库:git clone https://github.com/HumanSignal/labelImg.git 安装依赖:pip install pyqt5 lxml 运行工具:python labelImg.py 官方仓库 下载地址:https://github.com/HumanSignal/labelImg 提取码: 2. 标准标注流程 打开工具,点击“Open Dir”选择待标注图像文件夹 点击“Change Output Dir”选择标注文件保存路径 在菜单栏选择标注格式(PASCAL VOC/YOLO/CreateML) 点击“Create RectBox”或按快捷键W绘制边界框,选择预设标签 点击“Save”或按快捷键Ctrl+S保存标注,按D切换至下一张图像继续标注 工具总结 LabelImg是机器学习/深度学习领域的经典图像标注工具,凭借多格式兼容、操作高效、跨平台适配等核心优势,成为目标检测数据集制作的首选工具。无论是个人研究者快速标注小批量数据,还是团队制定规范标注大规模数据集,LabelImg都能提供稳定、高效的支持。
-
Drawnix开源在线白板工具源码 可视化协作SaaS平台 Drawnix开源在线白板工具源码 可视化协作SaaS平台 Drawnix是一款基于Web的开源白板工具,采用SaaS模式打造,是集思维导图绘制、流程图设计、自由创意绘图等多种功能于一体的可视化协作平台。项目采用现代化前端架构构建,原生兼容React、Angular等主流UI框架,具备极强的扩展性与可维护性。 mm95o4gr.png图片 项目技术底层与结构概览 底层核心框架 项目底层基于自主研发并开源的Plait图形绘制框架构建,沉淀了专业的知识图谱与可视化产品技术积累,实现了高度模块化、插件化的核心设计,为功能扩展与二次开发提供了坚实的技术底座。 项目核心结构 drawnix/ ├── apps/ │ └── web # 前端应用入口 │ └── index.html ├── dist/ # 构建输出目录 ├── packages/ │ └── drawnix/ │ ├── react-board/ # React 白板视图层 │ └── react-text/ # 文本渲染模块 ├── package.json └── README.md核心功能模块 1. 全场景绘图模式支持 思维导图:原生支持Markdown语法快速生成思维导图,适配知识整理、逻辑梳理、框架搭建等全场景需求 流程图:支持Mermaid语法一键自动转换为标准流程图,完美适配技术文档撰写、业务流程设计等专业场景 自由画布:提供无限制自由绘图能力,支持画笔手绘、图片插入等创意操作,满足各类个性化创意表达需求 2. 专业级编辑能力 完整覆盖基础编辑全操作,支持撤销(Undo)、重做(Redo)、复制、粘贴等核心操作;同时提供多图层精细化管理能力,支持画布内对象的自由拖拽、缩放与旋转,满足复杂图表的精细化编辑需求。 3. 数据安全与导出能力 多格式导出:支持将画布内容导出为PNG图片格式,以及专属JSON格式(.drawnix文件),兼顾分享传播与后期二次编辑需求 自动保存:内置浏览器本地自动保存机制,实时备份画布内容,有效防止意外操作导致的数据丢失 4. 极致交互与多端适配优化 无限画布:支持画布无限缩放与滚动,无边界创作空间,完美适配大型项目设计、复杂知识图谱搭建等大体积内容创作 响应式设计:全页面响应式适配,完美兼容移动端设备,原生支持触控操作,实现多端无缝创作体验 主题模式:内置亮色/暗色双主题切换能力,适配不同使用环境与视觉偏好,大幅提升长时间使用的用户体验 5. 灵活插件机制与扩展能力 基于插件化架构设计,原生兼容React、Angular等不同UI框架,以及Slate等主流富文本框架;支持开发者开发细粒度可复用插件,可无限拓展应用场景,包括但不限于集成第三方工具、AI辅助绘图、行业专属功能模块等。 源码核心特色 1. 完全开源,MIT协议授权 项目全程开源免费,采用宽松的MIT开源协议,允许所有用户自由使用、修改与分发源码,无论是企业商用、教育机构教学使用,还是个人开发者学习、二次开发、私有化部署,均无版权限制。 2. 插件化模块化架构设计 基于Plait图形绘制框架构建,全程采用模块化、插件化设计理念,功能模块解耦彻底,既便于日常维护与问题排查,也大幅降低了功能扩展的开发门槛,可灵活适配不同前端技术栈的集成需求。 3. 现代化成熟技术栈 项目核心技术依赖稳定成熟,生态完善,具体包括: Plait:自研专业图形绘制引擎 Slate.js:主流富文本编辑框架 Floating UI:轻量化弹出层组件库 技术栈社区活跃,开发文档完善,学习与二次开发门槛低,适配现代前端开发标准。 4. 超高自由度可定制化 原生支持自定义插件开发,可根据业务需求灵活拓展各类能力,包括自定义图形组件、AI辅助绘图插件、第三方数据格式导入导出、多语言国际化支持等,可深度定制为行业专属白板工具。 5. 多方式跨平台部署支持 提供两种便捷部署方式,适配不同使用场景与技术环境: npm本地安装运行: npm install npm run start Docker容器化部署: docker pull pubuzhixing/drawnix:latest 项目总结 Drawnix是一款集全场景绘图能力、极致扩展性与开源精神于一体的专业在线白板工具,其底层技术架构与插件化设计理念,完全贴合现代前端开发的先进方向。无论是个人用户需要一款轻量级、无版权限制的在线绘图工具,还是企业、开发者希望基于源码进行深度定制、二次开发,打造专属的可视化协作平台,Drawnix都是兼具实用性与拓展性的优质开源项目。 下载 下载地址:https://pan.quark.cn/s/6642f9779afb 提取码:
-
OmniTools开源多功能在线工具网站源码_v0.4.0 OmniTools开源多功能在线工具网站源码_v0.4.0 一款专为简化日常各类技术与非技术任务打造的自托管Web应用,一站式覆盖编码辅助、图像/视频处理、PDF操作、数据分析等多领域需求,无需切换多个零散工具平台即可高效完成工作。 mm7ppdgr.png图片 项目定位与发布 该项目以开源形式发布于GitHub,面向所有有工具需求的用户,无论是开发者、设计师还是普通办公/学习人群,都能找到适配的功能。 部署方式 支持通过Docker命令一键快速部署到个人或团队的自有服务器中,部署命令如下: docker run -d --name omni-tools --restart unless-stopped -p 8080:80 iib0011/omni-tools:latest核心安全保障 所有文件处理、数据计算均在用户本地浏览器客户端完成,不会上传任何文件或数据到服务器,从根源上保障了用户的隐私安全与数据安全。 功能模块 1. 多媒体处理 图像工具 图像缩放 图像格式转换 视频工具 视频剪辑 视频倒放 2. 文本与数据处理 文本工具 大小写转换 列表随机化 文本格式化 日期与时间工具 日期计算器 时区转换器 数学工具 生成质数 生成完全数 3. 数据格式工具 JSON工具 PDF工具 CSV工具 源码特色 1. 自托管 用户可将项目完全部署在自有服务器上,拥有对工具站的完全控制权,同时结合客户端处理特性,进一步强化隐私保护。 下载 下载地址:https://pan.quark.cn/s/fb86894545d4 提取码: 2. 轻量级 Docker镜像大小仅为28MB,部署过程极其迅速简便,同时大幅降低了服务器的资源消耗。 3. 易扩展性 项目基于React和TypeScript构建,使用Material UI作为设计框架,同时采用Iconify的图标库,技术栈清晰规范。开发者可通过脚本轻松创建新的工具,命令如下: npm run script:create:tool my-tool-name folder1/folder2对于位于多层嵌套目录下的工具,也可通过类似命令快速创建。 项目总结 OmniTools是一个强大而灵活的开源工具集合,适用于需要频繁处理各种类型文件和技术任务的个人和团队。它的自托管特性、轻量化设计以及对隐私的高度重视,使其成为替代零散在线工具的理想解决方案。
-
Java开源AI算命占卜项目_传统文化+AI的创新交互系统 Java开源AI算命占卜项目:传统文化+现代AI的创新交互系统 一款融合前沿AI算法与传统玄学文化的开源AI算命占卜系统,采用前后端分离架构,功能覆盖解卦、塔罗占卜、八字命理等核心场景,同时支持用户管理、历史记录、多语言框架、模型集成、支付功能等扩展能力,源码结构清晰、模块化设计,文档配置齐全,非常适合开发者学习研究或二次开发商用。 mm5mj4nd.png图片 一、核心技术架构 后端技术栈 编程语言:Java 21 核心框架:Spring Boot,保障系统高性能与可扩展性 数据存储:MySQL 8,用于持久化用户数据、占卜记录、支付配置等核心信息 性能优化:Redis缓存,提升高频访问数据的读取速度,满足高并发场景需求 前端技术栈 构建环境:NodeJS 20+ 核心框架:React,打造界面美观、交互流畅的用户端体验 交互方式:通过API调用后端服务完成所有核心业务逻辑 二、核心功能模块 1. 解卦功能 根据用户输入的生辰八字等关键信息,自动生成对应的卦象,并结合AI算法与传统解卦逻辑,生成兼具科学性与趣味性的个性化解析内容。 2. 塔罗占卜功能 支持多种塔罗牌抽牌模式,用户可根据自身需求选择不同的牌阵,系统结合AI算法对抽取的牌面进行深度解读,提供专属的运势建议。 3. 八字命理功能 分析用户的完整八字信息,从命局层次、性格特征、事业财运、感情婚姻、健康状况等多个维度进行预测,为用户提供全面的运势参考。 4. 支付功能 支持付费解锁高级功能,例如更详细的占卜解读、个性化定制服务、专属时空局辅助解析等,满足不同用户的需求层次。 三、扩展功能模块 1. 用户管理 包含完整的用户注册、登录、个人资料维护、密码找回等功能,保障用户账户安全与使用便捷性。 2. 历史记录 自动保存用户的所有占卜记录,用户可随时在个人中心查看历史解析内容,方便对比不同时间的运势变化。 3. 多语言框架 虽然目前系统仅支持中文,但整体框架设计允许开发者轻松添加其他语言,满足国际化运营需求。 4. 模型集成 支持接入不同的AI大模型或专业预测模型,开发者可根据自身需求替换或升级模型,以实现更精准、更个性化的预测效果。 5. 支付平台接口更换 系统默认提供易支付接口配置,但同时支持开发者更换为其他主流支付平台接口,适应不同的业务场景与运营需求。 四、源码核心特色 1. 技术栈先进 采用当前主流的前后端分离技术架构,后端Spring Boot、前端React、MySQL+Redis数据存储,技术成熟稳定,社区资源丰富,便于开发者学习与维护。 2. 开放性强 提供详细的开发文档与配置说明,开发者可快速上手部署与二次开发; 源码结构清晰,采用模块化设计,各功能模块相互独立,便于维护与扩展; 支持更换AI模型、支付平台接口等核心组件,灵活性极高。 3. 文化融合 将传统算命文化(解卦、八字命理、塔罗占卜等)与现代AI技术完美结合,既保留了传统文化的精髓,又通过AI算法提升了解析的个性化与趣味性,为用户提供了一种全新的算命占卜体验。 五、部署指南 前端部署 环境准备 安装NodeJS 20+版本; 确保后端服务(AI-Diviner-Server)已正常运行。 配置步骤 修改src/lib/untils.ts文件中的API_URL,设置为后端服务的完整地址(注意不要带最后的斜杠/); 依次运行以下命令完成项目依赖安装与打包: npm install npm run build 后端部署 环境准备 安装Java 21、MySQL 8以及Redis; 准备好自己的AI模型密钥和支付平台账户。 配置步骤 修改src/main/resources/application.yml文件,更新数据库和Redis的连接配置; 修改src/main/java/fun/diviner/ai/entity/Special.java文件中的authSecret字段,设置为自己的密钥; 在src/main/java/fun/diviner/ai/diviner/ai/AIModel.java中填入自己的AI模型密钥; 将项目根目录下的data.sql文件导入到MySQL数据库中; 修改数据库中core表的相关支付配置字段: yiPayId:易支付ID; yiPayMerchantPrivateKey:易支付商户私钥; yiPayPlatformPublicKey:易支付平台公钥; yiPayNoticeUrlPrefix:易支付后端回调前缀(如https://api.ai.diviner.fun); yiPayReturnUrl:易支付前端回调地址(填写前端网址); 依次运行以下命令完成项目依赖安装与打包: mvn clean package 使用以下命令启动项目: java -jar target/ai-diviner-1.0.0.jar下载 下载地址:https://pan.quark.cn/s/f5c7cdadc5b2 提取码: 六、项目总结 这款Java开源AI算命占卜项目是一款极具创新性的开源项目,它将AI技术与传统文化完美结合,为用户提供了一种全新的、兼具科学性与趣味性的算命占卜体验。无论是对于想了解传统文化的普通用户,还是希望学习前后端分离架构、AI模型集成、支付系统开发等技术的开发者来说,这款项目都具有很高的学习价值与商用潜力。
-
HTML 暗黑炫酷程序员个人主页源码 开源免费响应式可定制 HTML暗黑炫酷风程序员个人主页源码 开源免费可定制 这款专为程序员打造的暗黑风格个人主页源码,依托HTML、CSS与JavaScript三大核心技术栈开发,是适配程序员打造专属个人展示平台的优质模板。该源码以极具科技感的暗黑风格为核心设计基调,既贴合程序员的审美偏好,又配备了丰富的个性化定制选项,开发者可根据自身需求轻松修改,打造独属于自己的个人主页。无论是用来展示个人开发项目、分享技术博客内容,还是交流编程实战经验,这款源码都能全方位满足使用需求。 mld2tdvc.png图片 核心功能亮点 暗黑风格界面设计 采用当下热门的暗黑系界面设计,整体视觉效果炫酷且充满科技感,高度契合程序员的审美需求。同时,暗黑显示模式能有效减少屏幕光线对眼睛的刺激,缓解长时间浏览网页带来的眼部疲劳,更适合程序员日常的使用习惯。 全端响应式适配 源码支持完善的响应式设计,能够智能适配桌面电脑、平板电脑、智能手机等不同尺寸的终端设备,无需单独为不同设备做适配开发,无论访问者使用何种设备打开主页,都能获得流畅、舒适的浏览体验。 个人项目便捷展示 源码内置专门的项目展示模块,开发者可简单快捷地添加、编辑项目信息,包括项目名称、功能描述、项目截图以及项目地址等内容,能够直观、清晰地向访问者展示自身的技术实力与项目开发经验。 技术博客无缝集成 针对有技术博客的开发者,源码支持博客内容的集成展示,可将博客文章的链接或内容摘要添加至个人主页,让访问者能够直接在主页上浏览、跳转至博客内容,提升技术分享的便捷性。 社交媒体链接整合 源码设置了社交媒体链接专区,开发者可自由添加GitHub、LinkedIn、Twitter等主流技术社交平台的账号链接,方便行业伙伴、访问者进行关注与互动,搭建个人的技术社交桥梁。 源码专属特色 高度个性化可定制 提供多维度的自定义设置选项,覆盖页面颜色、字体样式、整体布局等多个方面,开发者可根据自身喜好打造专属视觉风格。同时源码的代码结构清晰明了,关键位置都配有详细注释,即便没有丰富前端开发经验的初学者,也能轻松上手修改。 丰富动画提升交互 为增强页面的交互体验,源码中融入了多种趣味动画效果,包含页面加载时的过渡动画、鼠标悬停元素时的动态效果等。这些动画让静态的网页变得生动有趣,还能有效引导访问者的注意力,提升页面的整体交互感。 优质代码保障性能 源码的编写严格遵循前端开发的最佳实践与行业编码规范,代码质量处于较高水平。不仅能为开发者提供优秀的代码风格参考,帮助其学习并提升前端开发能力,同时高质量的代码也从底层保障了个人主页运行的稳定性与流畅性。 开源免费零成本使用 该个人主页源码为开源免费的资源,开发者可自由下载、直接使用,也能根据实际需求进行二次开发与功能扩展。这一特性大幅降低了程序员打造个人主页的开发成本,让开发者无需投入额外成本就能拥有专属的展示平台。 总结 这款HTML暗黑炫酷风程序员个人主页源码,是一款兼顾实用性与美观性的优质模板,以暗黑风格为核心,搭配完善的功能模块与高度的可定制性,能充分满足程序员展示个人项目、分享技术内容的核心需求。同时其优质的代码编写、丰富的动画效果,以及开源免费的特性,让它成为程序员打造个人主页的优选模板。如果你正想搭建一个极具个性的程序员个人主页,这款功能齐全、上手简单的HTML源码绝对值得尝试。 下载 下载地址:https://pan.quark.cn/s/16e8d253a6d7 提取码:
-
华为花瓣测速 app 官方版_Android 专业网络测速工具下载 华为花瓣测速:专业手机网络测试工具,轻松掌握网络状态 在移动网络和WIFI网络高频使用的当下,一款精准的网络测速工具能帮我们快速掌握网络状况,华为花瓣测速便是这样一款专为Android用户打造的专业网络工具,其最新版为v4.8.0.303,软件大小39.31MB,于2023年11月23日完成更新,凭借全面的功能和便捷的操作,成为不少用户检测网络的首选。 mlchuz7p.png图片 华为花瓣测速是集成了移动网络与WIFI网络上传、下载测试,以及网络诊断功能的工具,适配运营商2G/3G/4G/5G全制式网络,同时也支持WIFI网络的各项测试,还能完成时延抖动测试与网络诊断,实时且准确地为用户反馈当前的网络状态,安装简单、操作便捷、结果精准是其核心特点,即使是网络操作新手,也能轻松上手使用。 这款软件的界面设计简洁友好,主打一键测速功能,点击后可快速出测试结果,无需复杂的操作步骤。测速结果的展示也十分全面,不仅能显示待测网络的运营商名称、测试的城市位置,还能清晰呈现Ping时延、上传速率、下载速率、网络抖动以及丢包率等关键网络指标,让用户对网络状况有全方位的了解。同时,软件还能帮助用户分析网络波动的原因,甚至支持对蹭网用户进行限速管理,助力用户打造更极速、稳定的网络环境。 在功能层面,华为花瓣测速做到了多维度覆盖,满足用户不同的网络检测需求。信号测试功能可专门检测Wifi信号,帮助用户寻找周边更强的Wifi信号源;网络诊断功能能精准检测当前网络的连接状况,快速定位网络问题的根源,让用户针对性解决网络故障;附近网速功能依托地图定位,直观展示周边其他用户的网速快慢,为用户选择网络提供参考;网速排名功能则会展示用户的网速在同类测试中的名次,让用户清晰知晓自己的网络速度水平。 下载 下载地址:https://pan.quark.cn/s/449bca259955 提取码: 除了基础的测速和诊断功能,华为花瓣测速还有不少实用的特色设计。软件可自动保存所有测试过的网速数据信息,方便用户后续查看和对比网络状态的变化;测速结果中会同步显示测试的服务器IP和用户的手机型号,让测试数据更具参考性;在测速过程中,会以实时图形的形式展示当前的下载或上传速度,让用户直观看到网速的实时变化;同时能全方位测试网络延迟、下载速度、上传速度等核心指标,让用户对网络的各项性能了如指掌。 无论是日常刷视频、玩游戏时想检测网络是否卡顿,还是办公时排查网络传输问题,亦或是发现网络变慢后寻找问题根源,华为花瓣测速都能凭借全面的功能和精准的测试结果,为用户提供有效的网络检测支持,是一款实用性极强的手机网络管理工具。
-
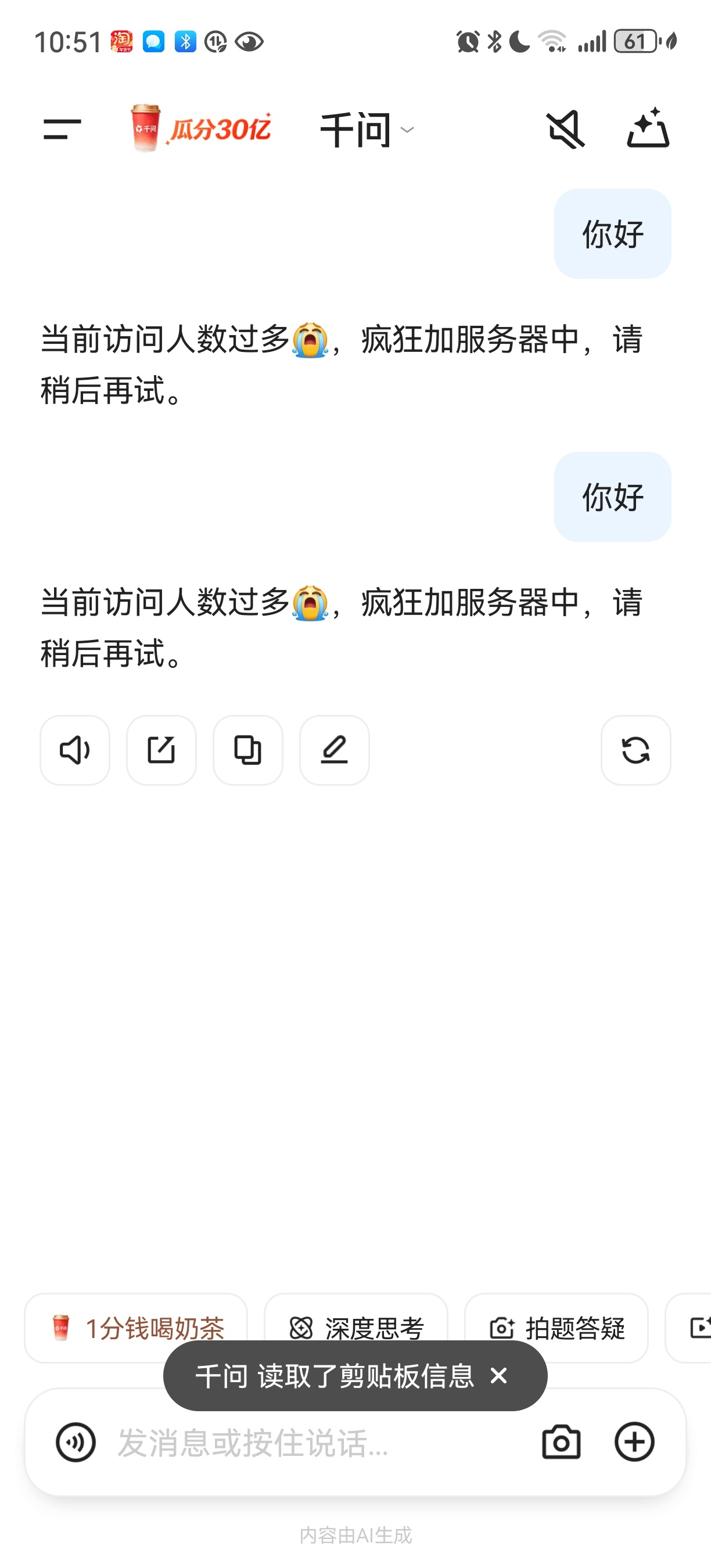
崩服预警!千问 30 亿免费奶茶硬刚元宝:登录领 25 元免单卡,无套路直喝 崩服预警!千问狂撒30亿请喝免费奶茶,硬刚元宝拉人头套路 “当前访问人数过多 😂,疯狂加服务器中,请稍后再试。” mlaamols.png图片 看着聊天框里重复弹出的过载提示,我才反应过来——不是我的网络出了问题,是千问的服务器,被全网想喝免费奶茶的网友们挤到“冒烟”了。这场号称“瓜分30亿”的福利活动,不仅是一次简单的用户回馈,更是千问针对腾讯元宝“拉人头红包”的一场正面反击战。 福利直给:1分钱喝奶茶,登录就领无套路 千问这次的宣传核心只有一个字:送。没有复杂的任务,没有烦人的社交裂变,主打一个“真诚换流量”。 ✅ 核心福利:登录千问即可领取25元无门槛免单卡,可直接兑换奶茶、咖啡、外卖等实物,相当于免费喝奶茶;另有10亿现金红包可抽,额外邀请好友还能解锁更多免单机会。 ✅ 参与入口:直接点击下方链接,跳过卡顿的聊天框,直达活动页面薅羊毛: 千问30亿免费奶茶活动入口 ✅ 活动亮点:哪怕不邀请任何好友,也能拿到基础免单卡,完美戳中用户对“拉人头套路”的反感点。 正面硬刚:千问VS元宝,AI红包大战的核心差异 正如你所洞察的,这场“免费奶茶”狂欢,本质是千问对腾讯元宝的精准反击。两大AI平台的红包活动,玩法差异堪称“套路与反套路”的对决: 对比维度千问(30亿福利)腾讯元宝(10亿现金)核心福利20亿免单卡(免费奶茶/外卖)+10亿现金纯现金红包参与门槛登录即领基础免单卡,无需拉人头必须分享链接邀请好友,才能获得抽奖次数活动逻辑降低门槛,用实物福利吸引泛用户绑定微信生态,靠社交裂变强制拉新用户体验无套路直给,好感度拉满分享压力大,易引发社交反感投入规模30亿总预算,元宝的3倍10亿现金,主打“现金诱惑”崩服的真相:用户用脚投票,反感“拉人头” 从“发送点奶茶指令无响应”到“统一弹出过载提示”,千问服务器的崩溃,恰恰印证了一个事实:用户早就受够了“拉人头”的套路。 腾讯元宝的现金红包虽然诱人,但“必须邀请好友”的规则,让很多人陷入“不分享就没福利”的尴尬;而千问的“免费奶茶”精准切中痛点——不需要麻烦亲友,不需要在朋友圈刷屏,点进链接就能领福利。这种“反套路”的玩法,直接引爆了用户热情,短时间内的流量洪峰,连大厂的服务器都没能扛住。 薅羊毛小贴士(避坑版) 目前千问已在紧急扩容,想要领到免费奶茶的网友,可以参考以下步骤: 切换网络 若页面显示“人数过多”,可错峰参与(避开10:00-12:00高峰时段); 领取免单卡后,尽快在活动页兑换奶茶,避免卡券过期; 邀请好友可额外领卡,但非强制,按需选择即可。 这场AI红包大战,千问用“免费奶茶”和“无套路”,在用户心智中狠狠刷了一波好感。虽然服务器崩了,但赢了人心——毕竟,谁能拒绝一杯不需要“拉人头”的免费奶茶呢?
-
YOLOv8自定义数据集制作与训练教程|训练专属检测模型 YOLOv8实战:从零制作自定义数据集,训练专属检测模型 前两章我们搞定了环境搭建和基础推理,能处理图片、视频,但用的都是官方预训练模型,只能检测80类通用目标(比如人、车、猫)。实际做项目时,肯定要检测自己的专属目标——比如检测工厂的零件缺陷、自家宠物、特定商品,这就需要做自定义数据集,训练专属模型。这一章全程手把手带做,从标注工具安装到训练出第一个自己的模型,所有步骤都拆到新手能看懂,代码直接复用。 ml7hddwt.png图片 一、前期准备:明确目标+选对工具 1. 先定检测目标(新手别贪多) 新手第一次做,别选太复杂的目标(比如检测细小的电子元件),选2-3类简单目标即可,比如: 日常物品:水杯(cup)、键盘(keyboard)、鼠标(mouse) 宠物类:自家的猫(cat)、狗(dog) 场景类:椅子(chair)、桌子(table) 我以“检测水杯、键盘、鼠标”为例,全程演示,你可以替换成自己要检测的目标。 2. 标注工具选LabelImg(新手首选) YOLOv8需要YOLO格式的标注文件,LabelImg是最经典、最容易上手的标注工具,支持一键导出YOLO格式,不用手动改格式,完美适配新手。 二、LabelImg安装(Windows/Mac通用) 1. 安装前置依赖 LabelImg基于Python和PyQt5,先装PyQt5: # Windows pip install pyqt5 lxml # Mac/Linux pip3 install pyqt5 lxml2. 安装LabelImg 两种方式,选一种就行: 方式1:pip直接安装(推荐) # Windows pip install labelimg # Mac/Linux pip3 install labelimg方式2:GitHub克隆安装(备用,解决pip安装失败) # 克隆仓库(需要装git,没装的话先装git) git clone https://github.com/HumanSignal/labelImg.git cd labelImg # 安装并运行 python setup.py install3. 验证安装(启动LabelImg) 打开终端,输入: # Windows/Mac通用 labelImg回车后会弹出LabelImg的可视化窗口,说明安装成功;如果报错“找不到命令”,重启终端或检查Python环境变量(上一章提过的PATH问题)。 三、制作YOLO格式自定义数据集(核心步骤) 1. 先建标准文件夹结构 YOLOv8对数据集路径、文件夹命名有严格要求,先按下面的结构建好文件夹(纯英文命名,别用中文/空格): my_custom_dataset/ # 总文件夹 ├── images/ # 图片文件夹 │ ├── train/ # 训练集图片(80%) │ └── val/ # 验证集图片(20%) └── labels/ # 标注文件文件夹 ├── train/ # 训练集标注文件(和train图片一一对应) └── val/ # 验证集标注文件(和val图片一一对应)操作步骤: 新建总文件夹my_custom_dataset,放在桌面(方便查找); 里面建images和labels两个子文件夹; images里再建train和val,labels同理。 2. 准备图片并划分训练/验证集 找20-50张包含“水杯、键盘、鼠标”的图片(数量不用多,新手先跑通流程); 选16-40张放入images/train(训练集,占80%),剩下的4-10张放入images/val(验证集,占20%); 所有图片重命名为纯英文+数字,比如img_001.jpg、img_002.jpg(避免中文/特殊字符报错)。 3. 用LabelImg标注图片(逐步教) 标注的核心是“给每张图片里的目标画框,指定类别,导出YOLO格式标注文件”,步骤如下: 步骤1:设置标注环境 打开LabelImg,点击左上角File → Change Save Dir,选择labels/train(先标注训练集); 点击左上角View,勾选Auto Save Mode(自动保存,不用手动点保存); 点击左侧YOLO(切换到YOLO标注格式,关键!默认是PascalVOC,要切换)。 步骤2:加载图片并标注 点击左上角Open Dir,选择images/train,加载训练集图片; 按快捷键W,调出标注框工具,用鼠标框选图片里的“水杯”; 弹出“Enter label”对话框,输入类别名(比如cup,小写!),点击OK; 继续框选同一张图里的“键盘”(输入keyboard)、“鼠标”(输入mouse); 按快捷键D,切换到下一张图片,重复标注; 标注完所有训练集图片后,同理切换Save Dir到labels/val,标注验证集图片。 步骤3:检查标注文件 标注完成后,labels/train和labels/val里会出现和图片同名的.txt文件(比如img_001.txt),这就是YOLO格式标注文件,打开一个看看,格式如下(每行代表一个目标): 0 0.45 0.52 0.30 0.40 # 类别编号 中心点x 中心点y 框宽 框高(都是归一化值,不用改) 1 0.78 0.65 0.25 0.354. 新建类别映射文件(classes.txt) 在my_custom_dataset根目录下,新建classes.txt文件,按顺序写入所有类别名(每行一个),比如: cup keyboard mouse这个文件用来关联“类别编号”和“类别名”,比如编号0对应cup,1对应keyboard,必须和标注时输入的名称一致! 四、编写数据集配置文件(yaml文件) YOLOv8训练需要一个yaml文件,告诉模型“数据集在哪、有多少类、类别名是什么”,这是新手最容易出错的环节,我直接给模板,你改路径和类别即可。 在my_custom_dataset根目录下,新建custom_dataset.yaml文件,内容如下(重点改path!): # 数据集根路径(绝对路径!新手别用相对路径,避免找不到) # Windows示例:path: C:/Users/你的用户名/Desktop/my_custom_dataset # Mac示例:path: /Users/你的用户名/Desktop/my_custom_dataset path: C:/Users/xxx/Desktop/my_custom_dataset # 训练集/验证集图片路径(基于上面的path,不用改) train: images/train val: images/val # 类别数(我这里是3类:cup、keyboard、mouse,按自己的改) nc: 3 # 类别名(和classes.txt一致,顺序也必须一致!) names: ['cup', 'keyboard', 'mouse'] ⚠️ 关键坑:path必须写绝对路径!比如Windows路径是C:/Users/张三/Desktop/my_custom_dataset(别用反斜杠\,用/),Mac路径是/Users/张三/Desktop/my_custom_dataset,写错路径训练时会提示“找不到数据集”。 五、训练自定义YOLOv8模型(核心代码) 所有准备工作完成后,训练代码非常简洁,基于ultralytics库一键训练,新手不用改复杂参数,先跑通再说。 完整训练代码 from ultralytics import YOLO # 1. 加载预训练模型(用yolov8s,轻量均衡,新手首选) model = YOLO('yolov8s.pt') # 2. 开始训练(核心参数只改data路径) results = model.train( data='C:/Users/xxx/Desktop/my_custom_dataset/custom_dataset.yaml', # 你的yaml文件绝对路径 epochs=50, # 训练轮数:新手50-100足够,数据少就少点(比如30) batch=8, # 批次大小:CPU/低配GPU设4-8,高配GPU设16-32 imgsz=640, # 输入图片尺寸:默认640,不用改 device=0, # 设备:0=GPU(有N卡就用),-1=CPU(无GPU) patience=10, # 早停:10轮没提升就停止,避免过拟合 save=True, # 自动保存最佳模型 project='runs/train',# 训练结果保存目录 name='custom_model' # 本次训练名称,方便区分 ) # 训练完成后,最佳模型会保存在 runs/train/custom_model/weights/best.pt print("训练完成!最佳模型路径:", results.save_dir + "/weights/best.pt")训练过程监控 运行代码后,终端会打印训练日志,重点看两个指标: mAP50:平均精度,数值越高(0-1),模型效果越好; loss:损失值,随着训练轮数增加,应该逐渐降低并趋于稳定。 训练过程中,还会自动生成runs/train/custom_model文件夹,里面有训练曲线图、验证集检测示例、模型权重文件,不用手动管。 六、用自定义模型推理(验证效果) 训练完成后,用自己训的best.pt模型检测图片,验证是否能识别自定义目标: from ultralytics import YOLO # 加载自己训练的最佳模型 model = YOLO('runs/train/custom_model/weights/best.pt') # 检测一张包含水杯/键盘/鼠标的图片 results = model( source='test_custom.jpg', # 自己的测试图片 conf=0.5, # 置信度调高,避免误检 save=True ) # 打印检测结果 print("自定义模型检测结果:") for box in results[0].boxes: class_name = results[0].names[int(box.cls)] confidence = round(float(box.conf), 2) print(f"目标:{class_name},置信度:{confidence}")运行后,会生成带标注框的结果图,能清晰看到自己标注的“cup/keyboard/mouse”被识别出来,就算训练成功了! 七、本章常见问题与解决方法 训练报错“Dataset not found” 原因:yaml文件里的path路径错误、数据集文件夹结构不对、图片/标注文件缺失 解决:核对绝对路径是否正确,确保images/train和labels/train里的文件一一对应(图片和txt文件名完全一致)。 训练时显存不足(CUDA out of memory) 原因:batch批次太大、模型版本太高(比如用yolov8l/x) 解决:把batch降到4甚至2,换回yolov8n/s模型,或用CPU训练(device=-1)。 标注文件报错“IndexError: list index out of range” 原因:类别编号超出范围(比如标注了4类,但yaml里nc=3)、classes.txt和标注类别名不一致 解决:核对nc数值和实际类别数一致,类别名大小写/拼写完全匹配。 训练完成后检测不到自定义目标 原因:标注图片数量太少、标注框不准确、训练轮数不够 解决:增加标注图片数量(至少20张),重新标注确保框准确,把epochs调到80-100。 八、本章小结 这一章我们完成了“自定义数据集制作→配置文件编写→模型训练→推理验证”的全流程,核心是“先搭对文件夹结构、选对标注格式、写对yaml路径”,这三个环节不出错,训练基本就能跑通。 新手第一次训练效果可能不完美(比如漏检、误检),不用急,后续可以通过增加标注数据、调整训练参数(比如batch、epochs)、优化标注质量来提升。下一章我们会专门讲“YOLOv8训练调参技巧”,教你怎么用最少的改动,让模型效果翻倍。
-
YOLOv8实战进阶|单图、视频、批量推理与基础参数调优教程 YOLOv8实战进阶:单图、视频、批量推理与基础参数调优 上一章我们完成了YOLOv8最基础的环境搭建和单张图片检测,成功跑出了第一个带标注框的结果。但在实际使用里,只处理单张静态图片远远不够,视频检测、批量图片处理、调整检测精度和速度,才是日常高频用到的功能。这一章就顺着上一章的代码,在不改动核心逻辑的前提下,扩展常用推理场景,同时讲清楚新手最先用到的几个参数,所有代码都可以直接复制运行,配合上一章的环境直接使用。 ml2hyuoz.png图片 一、模型规格切换与选用建议 YOLOv8官方提供了多种不同大小的预训练模型,分别是yolov8n、yolov8s、yolov8m、yolov8l、yolov8x,后缀字母对应模型参数量和计算量,直接影响检测速度和精度,新手可以根据硬件直接选择。 yolov8n:nano,最小最快,精度一般,适合CPU、低配设备、嵌入式端 yolov8s:small,轻量均衡,CPU运行流畅,精度比n版提升明显,日常测试首选 yolov8m:medium,中等规模,精度较好,建议有独立显卡使用 yolov8l:large,大模型,高精度,需要中端以上NVIDIA显卡 yolov8x:xlarge,最大模型,精度最高,对显卡显存要求高 模型切换不需要修改代码逻辑,只需要更换加载的模型文件名即可。上一章我们用的是yolov8n.pt,想要换成s版,只需要修改一行代码: from ultralytics import YOLO # 替换为yolov8s.pt,首次运行会自动下载模型文件 model = YOLO('yolov8s.pt')硬件配置普通、仅做学习测试,优先保留n版或s版;有GPU且追求检测效果,再逐步升级到m、l、x版,不建议新手一上来用大模型,容易出现加载慢、显存不足的问题。 二、单张图片推理进阶用法 基础单图检测只能实现默认检测和保存,实际使用中我们经常需要指定保存目录、关闭冗余输出、只提取检测结果数据,这里整理可直接使用的进阶代码。 from ultralytics import YOLO # 加载s版均衡模型 model = YOLO('yolov8s.pt') # 单图推理,增加常用参数 # source:图片路径 # conf:置信度阈值,低于该值的目标不显示 # save:是否保存结果图片 # project:保存结果的根文件夹 # name:本次推理的结果子文件夹 # verbose:关闭终端冗余日志输出 results = model( source='test.jpg', conf=0.3, save=True, project='runs/detect', name='my_single_result', verbose=False ) # 解析并结构化打印结果 print("=== 单图检测详细结果 ===") for idx, box in enumerate(results[0].boxes): cls_id = int(box.cls) class_name = results[0].names[cls_id] conf = round(float(box.conf), 2) # 检测框坐标信息 (x1, y1, x2, y2) xyxy = box.xyxy.cpu().numpy().tolist()[0] print(f"目标{idx+1} | 类别:{class_name} | 置信度:{conf} | 坐标:{xyxy}")运行后,结果会统一保存在runs/detect/my_single_result目录下,方便多次测试区分不同版本的输出,同时终端只打印结构化的关键信息,不会被大量日志干扰。 三、视频文件目标检测 图片检测是基础,视频检测是YOLOv8的高频实用场景,代码逻辑和单图完全一致,只需要将source参数替换为视频文件路径,模型会自动逐帧处理并输出带检测框的视频。 操作准备 准备一段常见格式的视频,如mp4、avi、mov,文件名改为英文,如test_video.mp4 将视频和代码文件放在同一目录 完整视频检测代码 from ultralytics import YOLO model = YOLO('yolov8s.pt') # 视频推理,新增帧率相关与保存参数 results = model( source='test_video.mp4', conf=0.3, save=True, project='runs/detect', name='my_video_result', verbose=False, # 保留视频音频,可选 save_audio=True ) print("视频检测完成,结果保存在runs/detect/my_video_result目录")硬件说明: CPU环境:可以处理短时长、低分辨率视频,处理速度慢于原视频帧率,属于正常现象 GPU环境:可以流畅处理1080P及以下视频,处理速度接近实时 输出的视频文件会自动存放在指定目录,文件名包含处理标识,可直接用播放器打开查看逐帧检测效果。 四、批量图片批量推理 日常工作中经常需要一次性处理一整个文件夹的图片,逐张手动运行效率太低,YOLOv8支持直接传入文件夹路径,自动批量处理所有图片,无需编写循环代码。 操作准备 新建一个文件夹,命名为batch_images 将所有需要检测的图片放入该文件夹,全部使用英文文件名 保证batch_images和代码文件在同一级目录 批量检测完整代码 from ultralytics import YOLO model = YOLO('yolov8s.pt') # 直接传入文件夹路径,批量处理所有图片 results = model( source='batch_images', conf=0.3, save=True, project='runs/detect', name='my_batch_result', verbose=False ) # 统计总检测数量 total_objects = 0 for res in results: total_objects += len(res.boxes) print(f"批量处理完成,共处理图片{len(results)}张,总计检测目标{total_objects}个") print("所有标注结果图片保存在runs/detect/my_batch_result目录")运行后,程序会遍历文件夹内所有合法图片,逐张检测并保存标注结果,终端输出整体统计数据,适合数据集预处理、批量标注预览等场景。 五、新手必用核心参数说明 上面代码用到的参数,是日常推理最常用的几个,不需要记复杂文档,理解这几个就足够完成大部分测试任务: source:输入源,可以是单张图片路径、视频路径、文件夹路径、摄像头编号 conf:置信度阈值,范围0-1,数值越高,检测结果越严格,误检越少,但可能漏检小目标,新手常用0.25-0.5 save:布尔值,True为保存带框的结果文件,False为只计算不保存 project:结果保存的根目录,统一管理所有输出,避免文件混乱 name:单次推理的子文件夹名称,方便区分不同参数、不同模型的测试结果 verbose:True输出完整日志,False关闭冗余输出,只保留关键信息 这些参数可以自由组合,比如高置信度严格检测、指定自定义保存目录、批量处理加精简日志,适配不同使用场景。 六、本章常见问题与解决方法 视频运行报错,提示无法读取视频 原因:视频格式不兼容、文件损坏、路径包含中文或空格 解决:转换为mp4格式,重命名为纯英文无空格路径,检查文件是否可正常播放 批量处理只识别部分图片 原因:部分图片格式非JPG/PNG、文件名异常、图片损坏 解决:统一转换为JPG格式,删除无法打开的损坏图片,全部使用英文命名 CPU处理视频速度极慢,甚至卡顿 原因:视频分辨率过高、模型版本偏大、CPU性能有限 解决:换回yolov8n模型,压缩视频分辨率为720P及以下,缩短视频时长 输出目录找不到结果文件 原因:project和name参数理解错误,默认路径和自定义路径混淆 解决:固定使用runs/detect作为根目录,每次修改name区分任务,直接按路径层级查找 检测结果大量误检,出现无效目标 原因:置信度conf设置过低 解决:将conf从0.25提高到0.35-0.4,过滤低置信度无效目标 七、本章小结 这一章我们没有引入新的环境配置,完全基于上一章的运行环境,扩展了单图进阶、视频、批量图片三种核心推理方式,同时讲清楚了模型规格选择和新手必用参数。可以发现,YOLOv8的推理接口设计非常统一,无论输入源是图片、视频还是文件夹,核心代码结构完全不变,只需要修改source和少量配置参数。 现阶段不需要深入理解模型底层原理,先熟练掌握不同输入源的推理写法、参数调整,能稳定处理图片和视频,完成日常测试需求,就已经达到入门实战的标准。下一章我们会进入自定义数据的准备环节,学习使用标注工具制作自己的数据集,为训练专属检测模型做准备。
-
YOLOv8新手入门|半小时从0到1跑通目标检测 前言 最近想入门目标检测,选了YOLOv8——毕竟是现在最主流的版本,官方文档也算友好,但作为纯新手,光看文档还是踩了不少细节坑。今天把“从装环境到跑出第一个检测结果”的全过程拆解得明明白白,主打一个“新手跟着做就能成”,先不抠复杂理论,咱先把代码跑起来、看到效果再说。 ml1blk9f.png图片 一、环境搭建:新手别贪新,稳最重要 YOLOv8依赖Python和几个核心库,版本不对会踩大坑,我先把每一步的操作和验证方法写清楚,按步骤来绝对不出错。 1. 第一步:确认Python版本(重中之重) YOLOv8对Python版本有要求,太高的版本(比如3.11、3.12)会和依赖库不兼容,我亲测3.8、3.9、3.10这三个版本最稳,优先选3.9。 怎么查Python版本?打开电脑的终端(Windows叫命令提示符/PowerShell,Mac/Linux叫终端),输入: python --version # 或(部分电脑需要用python3) python3 --version回车后会显示版本号,比如“Python 3.9.18”就是合格的;如果显示3.11+,建议先装3.9版本(网上搜“Python3.9安装”,按系统步骤装就行,新手选“添加到PATH”,避免后续路径问题)。 2. 第二步:升级pip(避免安装库时出错) pip是Python装库的工具,旧版本容易装错包、出现兼容性问题,先升级到最新版: # Windows系统 python -m pip install --upgrade pip # Mac/Linux系统 python3 -m pip install --upgrade pipml1aj4tv.png图片 看到“Successfully upgraded pip”就说明升级成功了,耐心等几秒就行,过程很快。 3. 第三步:安装YOLOv8核心库ultralytics ultralytics是官方维护的YOLOv8库,不用复杂配置,一行命令就能安装: # Windows系统 pip install ultralytics # Mac/Linux系统 pip3 install ultralyticsml1aydce.png图片 安装过程中会自动下载依赖的库(比如numpy、opencv、pillow等),不用手动干预。看到“Successfully installed ultralytics-xxx”(xxx是版本号),就说明核心库装好了。 4. 第四步:安装PyTorch(最容易踩坑的一步) ultralytics必须依赖PyTorch才能运行,但直接用pip装可能会装到不匹配的版本,尤其是有显卡的同学,一定要按自己的系统和硬件选对命令,新手优先装CPU版,稳妥不出错。 先判断自己要不要装GPU版:如果你电脑是N卡(NVIDIA),且提前装了CUDA(新手如果没装CUDA,别折腾,先装CPU版,后续熟悉了再升级GPU);AMD显卡或没有独立显卡的,直接装CPU版即可。 安装命令(复制对应版本,粘贴到终端执行): ① CPU版(所有系统通用,新手首选): # Windows/Mac/Linux通用 pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpuml1azc1e.png图片 ② GPU版(仅NVIDIA显卡,需先装CUDA 11.8/12.1): 去PyTorch官网(https://pytorch.org/get-started/locally/),按提示选择系统、CUDA版本,复制生成的命令。比如Windows系统+CUDA 11.8,命令如下: pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118ml1azqvu.png图片 验证PyTorch是否装对(必做步骤):装完后,在终端输入python(或python3)进入Python交互模式,依次输入两行代码: import torch print(torch.cuda.is_available()) # 有GPU且装对会显示True,CPU版显示Falseml1b0u3d.png图片 如果没报错,就说明PyTorch装对了。输入exit()退出Python交互模式,进入下一步。 5. 最终验证:确认YOLOv8能正常导入 这一步能提前排查问题,避免后续写好代码白忙活。在终端输入python(或python3),输入: from ultralytics import YOLO print("YOLOv8环境搭建完成!")ml1b1s6y.png图片 没报错、能正常打印这句话,说明整个环境搭建完全没问题了,可以开始写代码跑demo了。 二、写6行代码,跑通第一个目标检测(全程不踩坑) 环境搭好,接下来就是最有成就感的环节——跑通第一个检测demo!我把代码逐行注释,新手照抄就行,连路径问题都帮你考虑到了。 1. 准备测试图片 ① 找一张包含常见物体的图片(比如有猫、狗、人、杯子、汽车的图),别用带中文的图片名,会报错,重命名为test.jpg; ② 把图片放在一个容易找到的文件夹里,比如Windows的“桌面/YOLO_test”,Mac的“文稿/YOLO_test”,后续代码和图片放同一文件夹,不用记复杂路径。 2. 编写核心代码(逐行解释,新手能懂) 打开记事本(Windows)或文本编辑(Mac),复制下面的代码,保存为detect_test.py(同样别用中文文件名),和test.jpg放在同一个文件夹里: # 1. 导入YOLO库(环境搭好才能正常导入,报错先查环境) from ultralytics import YOLO # 2. 加载YOLOv8预训练模型:选yolov8n(n代表nano,最轻量,运行最快,新手优先) # 第一次运行会自动下载yolov8n.pt模型文件,耐心等几秒(网络差可手动下载) model = YOLO('yolov8n.pt') # 3. 执行目标检测:传入图片路径,conf=0.25代表置信度(低于25%的目标不识别,避免误检) results = model('test.jpg', conf=0.25) # 4. 保存检测后的图片(自动画彩色框,标注目标名称和置信度) results[0].save('result.jpg') # 5. 打印检测结果:清晰显示识别到的目标和置信度 print("检测完成!以下是识别到的目标:") for box in results[0].boxes: # box.cls是目标类别编号,results[0].names是编号对应的类别名 class_name = results[0].names[int(box.cls)] # box.conf是置信度,保留两位小数,更易读 confidence = round(float(box.conf), 2) print(f"目标:{class_name},置信度:{confidence}")ml1bi7ts.png图片 有点不准(bushi) 3. 运行代码(两种方式,选一种就行) 方式1:终端运行(推荐,新手易排查问题) ① 打开终端,切换到图片和代码所在的文件夹: Windows系统(比如文件在桌面YOLO_test文件夹): cd Desktop/YOLO_testMac系统(比如文件在文稿YOLO_test文件夹): cd ~/Documents/YOLO_test② 输入运行命令,执行代码: # Windows系统 python detect_test.py # Mac/Linux系统 python3 detect_test.py方式2:用IDE运行(比如PyCharm、VS Code) ① 打开PyCharm/VS Code,导入存放代码和图片的文件夹; ② 右键点击detect_test.py文件,选择“Run”(运行),等待执行完成即可。 4. 查看检测结果(重点看这两个地方) ① 查看结果图片:文件夹里会多出result.jpg,打开后能看到图片上有彩色边框,边框旁标注了目标名称(比如cat、person、cup)和置信度,一目了然; ② 查看终端输出:终端会打印出识别到的目标和对应置信度,比如“目标:cat,置信度:0.92”,能清晰知道模型识别结果; 补充:如果没在文件夹根目录找到result.jpg,去runs/detect/predict目录找——这是YOLOv8默认的结果保存路径,第一次运行会自动生成这个文件夹,结果图一定在里面。 三、新手必看:我踩过的坑和解决方法 我第一次操作时,光环境搭建就耗了1小时,全是踩坑踩出来的经验,这几个坑新手大概率会遇到,提前记好解决方案: 1. 坑1:运行代码报“FileNotFoundError: test.jpg” 原因:图片路径错误,要么图片和代码不在同一文件夹,要么图片名写错(比如多打了空格、用了中文)。 解决:① 确认test.jpg和detect_test.py在同一文件夹;② 图片名必须是纯英文+后缀,无空格;③ 实在搞不定路径,就写绝对路径,比如Windows:model('C:/Users/你的用户名/Desktop/YOLO_test/test.jpg'),Mac:model('/Users/你的用户名/Documents/YOLO_test/test.jpg')。 2. 坑2:下载yolov8n.pt模型超时、失败 原因:网络问题,模型文件在国外服务器,国内网络下载容易卡顿超时。 解决:手动下载模型(网上搜“yolov8n.pt 官方下载”,从ultralytics官网或可信平台下载),把下载好的yolov8n.pt文件放到代码所在文件夹,代码会自动读取本地模型,不用再在线下载。 3. 坑3:导入YOLO时报“ImportError: Missing required dependencies ['torch']” 原因:PyTorch没装对,或版本不兼容,导致YOLO库无法调用。 解决:先卸载现有PyTorch,再重新安装。卸载命令:pip uninstall torch torchvision torchaudio,然后按前面的步骤重新装CPU版PyTorch,基本能解决。 4. 坑4:Mac运行报“OSError: dlopen(libtorch.dylib, 0x0006): Library not loaded” 原因:Mac系统Python环境混乱,库依赖路径不对。 解决:用Anaconda创建独立环境(新手搜“Anaconda安装教程”,很简单),创建Python3.9的环境后,在该环境下重新装ultralytics和PyTorch,就能避免路径冲突。 四、新手碎碎念 其实新手入门YOLOv8,最容易犯的错就是“追求新版本”“急于抠理论”——一开始我非要装Python3.12,结果各种兼容问题,换成3.9后瞬间顺畅;还总想着先搞懂“锚框”“特征提取”,越看越懵,反而打击积极性。 后来发现,先把代码跑起来、看到检测结果,有了成就感再回头补理论,效率会高很多。这篇教程主打“能跑就行”,把环境搭建、代码运行的每一步都拆碎,甚至把命令都写死,就是希望新手能少走弯路,快速get到目标检测的乐趣。 下一篇我会讲YOLOv8的拓展玩法——分割、姿态估计,其实就改一行代码的事,新手也能轻松上手,咱们下篇见。
-
HTML响应式天气预报网站源码_多端适配天气模板免费下载 HTML响应式天气预报网站源码 原生前端开发的多端适配天气网站搭建模板,无复杂部署与环境依赖,可直接用于快速搭建独立天气查询网站,也能无缝集成到现有站点作为功能模块,源码可扩展性强,适合前端开发二次定制开发。 ml0uvz1c.png图片 一、核心技术架构 基于前端原生技术栈开发,全程无后端服务、数据库依赖,开发和部署门槛极低,核心技术实现细节如下: 采用HTML5语义化标签构建页面结构,让代码可读性更强,同时适配搜索引擎抓取规则,兼顾基础SEO需求 以CSS3原生特性实现样式渲染,结合弹性布局、网格布局及媒体查询,打造全终端自适应的响应式布局,无需单独开发移动端、桌面端版本 原生JavaScript实现所有交互逻辑,包含异步API请求、数据解析渲染、城市选择交互、多城市数据管理等核心功能,无第三方框架冗余代码 基于AJAX/Fetch实现与公开天气API的对接,完成气象数据的异步获取与实时渲染,请求逻辑解耦,便于替换不同的天气数据接口 二、核心功能模块 功能覆盖天气查询的核心使用场景,模块划分清晰,交互逻辑简洁,所有功能均可直接使用或按需修改: 1. 城市天气精准查询 支持两种查询方式,一是手动输入城市名称快速检索,二是通过城市选择器分类选择,查询后实时渲染目标城市的核心气象数据,包含实时温度、空气湿度、风速、风向、天气状况等关键信息,数据展示直观无冗余。 2. 多日天气趋势预报 展示目标城市未来数日的气象趋势,按日期维度拆分,每个日期均展示最高温、最低温、实时天气状况,部分日期可展示时段性气象变化,满足用户提前规划出行的核心需求。 3. 多城市天气管理与对比 支持多城市添加、收藏与删除,可将常用城市加入收藏列表,收藏后多城市天气数据同屏展示,实现不同城市气象数据的直观对比,适配跨城市出行、异地生活等使用场景。 4. 天气状态可视化展示 所有天气状况均以图标化形式呈现,晴、雨、雪、雾、多云等状态对应专属视觉图标,搭配数值化的气象数据,让用户快速获取核心信息,视觉体验与使用体验兼顾。 三、源码核心优势 贴合前端开发的实际需求,从代码质量、使用体验、二次开发三个维度打造核心优势,适配个人开发、站点功能集成等多种场景: 代码质量高:无冗余代码、无无效嵌套,HTML、CSS、JS文件分离管理,变量与函数命名规范,注释简洁且仅标注核心逻辑,便于开发者快速理解代码结构 轻量且高效:原生开发无框架打包体积冗余,页面加载速度快,运行过程中无卡顿,在低配设备、弱网络环境下仍能保持流畅的使用体验 兼容性强:兼容Chrome、Firefox、Edge、Safari等所有主流浏览器,同时适配手机、平板、笔记本、台式机等全尺寸设备,无兼容适配问题 二次开发成本低:所有功能模块均做解耦处理,API请求、数据渲染、交互逻辑相互独立,可单独修改某一模块而不影响整体功能,支持按需增删、修改功能 四、二次开发拓展方向 基于现有源码结构,可快速拓展各类实用功能,无需重构核心代码,以下为贴合实际使用的拓展方向,均能基于原生前端技术实现: 新增空气质量监测模块,对接空气质量AQI接口,展示空气质量等级、PM2.5、PM10、臭氧等核心数据,标注空气质量适宜程度 加入生活气象指数,包含穿衣、出行、防晒、洗车、运动等实用指数,根据实时气象数据自动匹配推荐建议,提升网站实用性 实现自动定位功能,基于浏览器原生Geolocation获取用户所在位置,自动加载本地天气数据,减少用户手动操作步骤 新增气象预警功能,对接气象预警接口,实时展示暴雨、大风、高温、寒潮等气象预警信息,标注预警等级与影响范围 升级数据可视化效果,添加温度趋势折线图、湿度/风速柱状图,让气象数据的变化趋势更直观 增加个性化设置功能,支持背景随天气状态自动切换、摄氏度/华氏度单位切换、数据刷新时间自定义等 加入历史气象数据查询,支持按日期检索目标城市的历史气象信息,丰富网站数据维度 五、适用场景 个人开发者快速搭建专属的独立天气查询网站,或为自有站点集成天气查询功能模块,丰富站点功能 前端学习者作为原生JavaScript+HTML5+CSS3的实战学习案例,掌握响应式布局、异步API请求、前端交互逻辑的核心实现 小型站点快速上线配套的天气查询功能,无需投入大量开发成本,基于源码快速定制即可使用 下载 下载地址:https://pan.quark.cn/s/6491a56ac441 提取码:
-
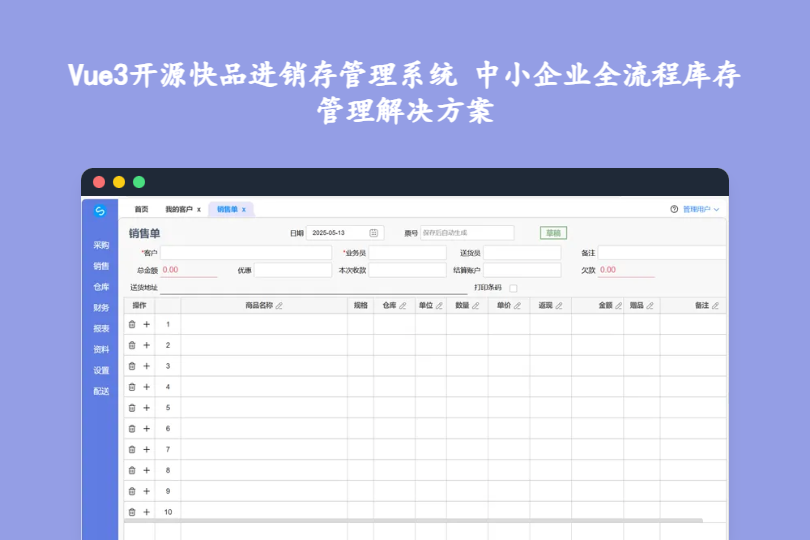
Vue3开源快品进销存管理系统 中小企业全流程库存管理解决方案 Vue3开源在线快品进销存管理系统源码:中小企业全流程库存管理解决方案 这款系统是基于Vue3+Node.js+Mssql构建的开源快消品进销存管理工具,以木兰宽松许可证第2版授权,主打全流程数字化管理,覆盖采购、销售、仓库、财务、配送五大核心环节,操作简便且拓展性强,专为中小企业快消品业务打造,大幅降低库存与运营管理成本。 mky8r438.png图片 一、核心技术架构:现代化栈,稳定高效 前端框架:采用Vue3开发,依托响应式编程与组件化设计优势,打造流畅易用的操作界面,支持多终端适配,不同屏幕尺寸下体验一致; 后端支撑:基于Node.js开发API接口,具备高并发处理能力,可稳定应对企业日常订单与库存数据的流转需求; 数据存储:选用Mssql数据库,支持复杂数据查询与事务处理,保障采购、销售、库存等核心数据的安全与准确; 授权与部署:遵循木兰宽松许可证第2版,可自由使用、修改与分发源码;支持本地服务器与云服务器部署,无需复杂配置即可上线。 二、核心功能模块:覆盖快消品进销存全流程 1. 采购管理 支持供应商信息管理,可维护供应商基本资料、联系方式与历史供货记录; 支持采购订单的创建、编辑、审核与跟踪,实现采购流程自动化; 采购入库时自动关联订单,同步更新库存数据,避免手动录入误差。 2. 销售管理 支持客户信息建档,涵盖客户基本资料、购买记录与信用额度设置; 支持销售订单的快速创建、修改、发货与退货操作,流程清晰可控; 销售出库时自动扣减对应商品库存,同步生成销售票据,便于财务对账。 3. 仓库管理 支持库存实时监控,可查看商品库存数量、存放位置与状态; 支持库存调拨、盘点与报废处理,帮助企业优化库存结构,减少商品积压; 支持多仓库、多货位管理,适配企业规模化仓储需求。 4. 财务管理 支持应收应付账款管理,跟踪销售回款与采购付款进度; 自动生成销售、采购、库存等多维度报表,为企业决策提供数据支撑; 支持商品成本、运输成本、仓储成本核算,助力企业精准控制运营成本。 5. 配送管理(特色功能) 可根据销售订单自动分配配送任务给对应配送员; 配送员可通过扫描销售票据二维码,快速完成出货核验; 支持配送状态实时跟踪,同步更新给客户,提升客户满意度。 三、源码核心特色 技术先进,体验流畅 基于Vue3+Node.js技术栈开发,系统性能稳定且可扩展性强;响应式设计适配多设备,操作流程简洁,降低员工学习门槛。 功能全面,流程闭环 覆盖从采购入库到销售出库、财务核算、物流配送的全流程管理,实现快消品业务的数字化闭环,提升运营效率。 易于集成,灵活定制 采用模块化设计,可根据企业需求新增功能模块;开放API接口,支持与ERP、CRM等其他企业系统集成。 开源免费,成本可控 遵循木兰宽松许可证第2版,企业可免费使用、修改源码,无需支付软件授权费用,大幅降低信息化建设成本。 四、适用场景 快消品中小企业:如零食、饮料、日用品批发商与零售商,用于管理库存、订单与配送业务; 创业团队:低成本搭建进销存管理系统,快速实现业务数字化; 技术开发团队:作为Vue3+Node.js实战项目,学习进销存系统架构设计,或基于源码定制化开发行业专属方案。 下载 下载 下载地址:https://pan.quark.cn/s/7a6eb3cea7cc 提取码: